
![]()
![]()
![]()
![]()
This document was made by OCR
from a scan of the technical report. It has not been edited or proofread and is
not meant for human consumption, but only for search engines. To see the
scanned original, replace OCR.htm with Abstract.htm or Abstract.html in the URL
that got you here.
INFORMATION AND COMPUTATION 76, 278-346 (1988)
+I
Pebble, a Kernel
Language for
Modules and Abstract Data Types*
B. LAMPSONt AND R. BURSTALLt
%Systems Research Center, Digital
Equipment Corporation,
130 Lytton Ave., Palo Alto, California 94301;
and
1Department of Computer Science, University of Edinburgh,
Kings Buildings,
Mayfield Road, Edinburgh •119 3JZ, Scotland
A small set of constructs can simulate a wide variety of
apparently distinct features
in modern programming languages. Using a kernel language called Pebble based on the typed lambda calculus
with bindings, declarations, dependent types, and types as compile time values, we show how to
build modules, interfaces and implementations, abstract data types, generic types, recursive types, and
unions. Pebble has a
concise operational semantics given by inference rules. 1988
Academic Press, Inc.
I. INTRODUCTION
Programming language designers have invented a
number of features to support the writing of large programs in a
modular way which takes advantage of type-checking. As languages have
grown in size these features have been added to the basic
structure of expressions, statements, and procedures in various ad hoc
fashions, increasing the syntactic and semantic complexity of
the language. It is not very clear what the underlying concepts
or the language design options are. In particular cases various kinds of
parameterised types or modules are offered, and it is unclear how these are
related to the ideas of function definition and application, which can be formalised
very simply in the lambda calculus.
This paper describes a relatively small
programming language called Pebble, which provides a
precise model for these features. It. is a functional language, based upon the
lambda calculus with types. It is addressed to the problems
of data types, abstract data types, and modules. It also deals with
•
This work was supported in part by the Xerox Palo Alto Research Center. An
earlier version was
presented at the International Symposium on Semantics of Data Types in Sophia-Antipolis, France, in June
of 1984, and appears in the proceedings of that symposium, "Lecture Notes in Computer
Science, Vol 173" (G. Kahn, D. B. MacQueen, and G. Plotkin, Eds.), pp. 1-50, Springer-Verlag, Berlin/New York.
278
0890-5401/88 S3.00
Copyright 4'• 1988 by Academic Press,
Inc.
All rights of reprodudion in any form reserved.
the idea of generic values. It does not reflect
all aspects of programming languages, since we have not dealt with
assignment, exceptions, or con-currency, although we
believe that these could be added to our framework. Our
intention is that it should be possible to express the semantics of a sizeable
part of a real programming language by giving rules which rewrite it
into Pebble. This follows the method used by Bauer and his colleagues (Bauer
et al., 1978)
to express the semantics of their wide spectrum language. We were
particularly concerned with the Cedar language (an extension of Mesa (Mitchell et al., 1979)) which is in use at
Xerox PARC. One of us has defined the quite complex part of this
language which is concerned with data types and modules in terms of
rewrite rules which convert Cedar to an earlier version
of Pebble (Lampson, 1983).
An earlier version of this paper appeared as (Burstall and
Lampson, 1984). In revising it we have
— provided
a better treatment of union types;
— introduced
the notion of "extended type" which enables us to carry around
the operations appropriate to a value as part of its type;
— introduced
a type constructor "0" which enables one to apply a polymorphic
function without giving an explicit type argument;
— introduced
a notion of inclusion between bindings so that a module can
accept a bigger binding than the one it needs;
— introduced
a coercion mechanism to implement these last two features;
— corrected
a mistake in the semantics of recursion.
We have also removed a number of minor errors and
infelicities. These changes in the direction of practicality have
enlarged somewhat the original small language which was
intended primarily to explicate the concepts, of modules
and system modelling. The original simplicity may still be discerned
with the eye of faith.
This paper was mostly written in 1983.
(Refereeing and revising the Journal version took some
time.) Since then the world has moved along and people have become
much more familiar with existential and universal
, dependent types due to the growing appreciation of
Martin-Lof s work on type theory. If we were rewriting it today we
might be more concise and less pedagogical in the first part of the paper.
None the less our aims have been somewhat different
from those of most people concerned with type theory. Starting
from our original concern with the module structure of Cedar,
we are now trying to design a language which could be a firm basis for
a practical system programming language. We have kept our formal semantics
fairly close to a possible practical implementation.
Recently we have made some simplifications in
Pebble, profiting from work by Luca Cardelli (1986) on a Pebble-like
language with a denotational semantics. We have a version of the
language with simpler operational semantics and we have added exceptions and
assignment. However, it is a sizeable task to write a new paper on the basis of
our new formal semantics, so we have decided to publish the
present version in the meantime.
The first part of this paper is informal with
examples, addressed to the language designer or user. The reader may or may
not wish to dig into the precise semantic definition in Sections 4 and 5.
For a less
detailed exposition of Pebble stressing motivation see Burstall
(1984).
Practical Motivation
A principal idea which we wish to express in our
formalism is the linking together of a number of modules into a large
program. This may be summarized as follows: Each program module produces
an implementation of
some collection of data types and procedures. In order to
do so it may require the implementations supplied to it by
some other modules. This traffic in implementations is controlled by interfaces which say what kind
of implementation is required or produced by a module.
These interfaces name the data types and specify the argument and result types
of the procedures. Given a large collection of modules, perhaps
the work of many people at different times, it is essential to be
able to express easily different ways of connecting them
together, that is, ways of providing the implementations
needed by each module. An input interface of a module may he satisfied
by the implementations produced by several different modules or different
"versions" of the same module.
We believe that linking should not be described
in a primitive and ad hoc special purpose language; it deserves more
systematic treatment. In our view the linking should he
expressed in a functional applicative language, in which modules
arc regarded as functions from
implementations to implementations. Furthermore this language should
be typed, and the interfaces should play the role of types for the
implementations. Thus we have the correspondence
implementation value
interface
+-• type
module 4–, function.
Function application is more appropriate for linking than
schemes based on the names of the modules and the sequence in
which they are presented. By choosing suitable structured types in a
functional language we can get a
simple notation for dealing with "big" objects
(pieces of a program) as if they were "small"
ones (numbers); this is the basic good trick in matrix algebra. Thus we hope to
make "Programming in the Large" look very much
like "Programming in the Small."
Another advantage of this approach to linking is
that the linking language can be incorporated in the programming language. We
hope in this way to achieve both conceptual economy and added
flexibility in expressing linking. By contrast, the usual
approach to the linking problem, exemplified by Mesa and
C-Mesa (Mitchell et a!. 1979),
has a programming language (Mesa) with a separate and
different linking language (C-Mesa) which sits on top of it so to speak.
The main advantage of this approach is that a separate linking language can
be used for linking modules of more than one programming language, although in
the past this advantage has been gained only at the price of using an extremely
primitive linking language.
A linking system called the System Modeller was
built by Eric Schmidt for his Ph. D. thesis work, supervised by one of us
(B.L.). He used an earlier version of Pebble with some modifications, notably
to provide default values for arguments since these are often obvious
from the context (Schmidt, 1982; Lampson and Schmidt, 1983). The System Modeller was used
several people to build large systems, but the implementation has not been
polished sufficiently for widespread use.
Our other practical motivation was to investigate
how to provide polymorphic functions
in Cedar, that is ones which will work uniformly for argument
values of different types; for example, a matrix transpose procedure
should work for integer matrices as well as for real matrices.
There have been two
experimental implementations of Pebble, one by Glenn Stone at
Manchester University in Prolog, and one by Hugh Stabler at
Edinburgh University in ML. These were both student projects. There have
been several other partial implementations.
Outline
of the Paper
We start from Landin's view of programming
languages as lambda calculus sweetened with syntactic sugar (Landin, 1964). Since we are dealing
with typed languages, we must use typed lambda calculus, but it turns out
that we need to go further and extend the type system with dependent types.
We take types as values, although they need to be handled only during
type-checking (which may involve some evaluation) and not at execution
time. We thus handle all variable binding with just one kind of lambda expression,
as opposed to.Reynolds (1974). Another extension is needed
because, while procedures accept n-tuples of values, for example, (I,
5, 3), at the module level it is burdensome to rely on position in a sequence
to identify parameters and it is usual to associate them with
names, for example (x-1, y 5, z— 3), This leads to the notion
of a hinding. To
elucidate the notion of a parameterised module we include such bindings
as values in Pebble. It turns out that the scoping of the names which
they contain does not create problems.
To define a precise meaning for Pebble programs
we give an operational semantics in the form of inference rules, using
a formalism due to Plotkin (1981), with
some variations. We could have attempted a dcnotational semantics,
but this would have raised theoretical questions rather different from our
concerns about language design. As far as we know it would be quite possible to
give a satisfactory denotational semantics for Pebble. Cardelli
(1986) gives a denotational
semantics for a quite similar language. Our semantics gives rules
for type-checking as well as evaluation. Our rules are
in fact deterministic and hence can be translated into an interpreter in a conventional
programming language such as Pascal.
Related Work
Our work is of course much indebted to that of
others. Reynolds, in a pioneering effort, treated the idea of
polymorphic types by introducing a special kind of lambda
expression (Reynolds, 1974) and McCracken built on this approach
(McCracken, 1979). The language Russell introduced dependent
types for functions and later for products (Demers and Donahue,
1980). MacQueen and Sethi have done some elegant work on the
semantics of a statically typed lambda calculus with dependent types (MacQueen
and Sethi. 1982), using the idea that these should be expressed by
quantified types: this idea of universally and existentially quantified types
was introduced in logic by Girard (Girard, 1972) and used by Martin-Lof
(Martin-Lof, 1973) for the constructive logic of mathematics. Mitchell
and Plotkin seem to have independently noted the usefulness of existentially
quantified types for explaining data abstraction (Plotkin and Mitchell,
1985). We had already noted this utility for dependent products, learning
later of the work on Russell and the connection with quantified types. It is a
little hard to know who first made these observations; they seem
to have been very much "in the air."
A notable difference between our approach and
that of others using quantified types is that we take types as values
and have have only one kind of lambda expression. Russell also takes
types as values, but they are abstract data types with operations, whereas we
start with types viewed as simple predicates without operations, building
more complex types from this simple basis. The idea of taking bindings
as values also appears in (Plotkin, 1981) with a somewhat similar motivation. Our work has been influenced
by previous work by one of us with Goguen on the design of the specification
language Clear (Burstall and Goguen, 1977).
2. INFORMAL
DESCRIPTION OF PEBBLE
This section describes the language, with some
brief examples and some motivation. We first go through the conventional
features such as expressions, conditionals, and function
definitions. Then we present those which have more interest:
- the
use of bindings as values with declarations as their types;
- the
use of types as values (at compile time);
- the
extension of function and product types to dependent types;
- the
method of defining polymorphic functions.
Finally we say something about type-checking.
The reader may wish to consult the formal description of
values and the formal syntax, given in Section 4, when he is
unclear about some point. Likewise the operational semantics, given in
Section 5, will clarify exact details of the
type-checking and evaluation.
2.1. Basic
Features
Pebble is based upon lambda calculus with types,
using a fairly conventional notation. It is entirely functional and
consists of expressions which denote values. This distinction
between expressions and values is in accord with our desire to
keep our semantics quite close to a practical implementation;
for example, we choose to use closures as the values of lambda expressions.
Note that in passing from expressions to values we lose type information,
e.g., in passing from a binding expression to a binding value or
from a lambda expression to a closure.
We start by describing the values, which we write
in this font for the remainder of this section. They are:
- primitive
values: integers and booleans;
- function
values: primitive operations, such as +, and closures which are the values of
lambda expressions;
- tuples:
nil and pairs of values, such as [1, 2];
- bindings:
values such as x 3 which associate a name with a value, sets
of these values which associate sets of names and values, and fix bindings
which arise in defining recursive functions;
- types
the primitive types int and bool
types
formed by x and -+
dependent
types formed by 0 and void, the type whose only element is nil
inferred product types formed by ig
extended
types formed by xt
the
type type which is the type of all types including itself, and declarations,
such as x: int, which are the types of bindings;
— symbolic
applications: these consist of a function value applied to an argument,
written P. e. They arise during type-checking. These are not final values
of expressions, but are used in the formal semantics.
We now consider the various
forms of expressions, putting aside for the moment the details
of bindings, declarations, and dependent types, which will
be discussed in later sections. These are as follows:
— applications:
these are of the form "operator operand," for example, .factorial 6,
with juxtaposition to denote application. Parentheses and brackets
are used purely for grouping. If E, is
an expression of type I, 17 and E2 is an expression of type 11, then
E, E2 is an expression of type 12. As
an abbreviation we allow infixed operators such as x+ y for
+ [x, y].
— tuples:
nil is an expression of type void. If E, is an expression
of type I, and
E2 one
of type 12 then [E,, E2] is an expression of type 1, x
12. The brackets are not significant and may be omitted. The
functions fst and snd select components, thus fst[ I, 2] is I.
— conditionals:
IF E, THEN
E2
ELSE E3 where E, is of type bool.
—-
local definitions: LET B IN
E evaluates
E in the environment enriched
by the binding B. For
example,
LET x: int — )7+ z IN
x + abs x
first evaluates y+ z and then evaluates
x + abs x with this value for x. The int may be omitted, thus
LET x y+z IN...
The binding may be recursive, thus
LET RECf: tint int)—... IN...
We allow E WHERE B as
an abbreviation for LET B in E.
— function
definitions: functions are denoted by lambda expressions, for
example,
Ax: int int IN x+ abs x
which when applied to 3 evaluates 3 + abs 3. yielding 6.
If T, evaluates
to 1, T2 evaluates
to 17, and
E is an expression of type 12,
then
is a function of
type ti The result type T2
may be omitted. Thus
Ax: int
IN x +abs x
defines
the same function as the previous example. Functions of two or more arguments
can be defined by using x, for example,
Ax: int x y: bool —+ int IN...
We allow the abbreviation
f(i: int int) :—...
for
f: (int
—n
int)— Ai: int -4 int IN...
An example may help to make this all more digestible:
LET
REC fact(n: int int)
:‑
IF n =0 THEN
I ELSE n *fact(n — 1)
IN LET k :— 2
+ 2 + 2 IN
fact(fst[k, k + I])
This all evaluates to factorial 6. Slightly less dull is
LET twice((f:
int int) (int int)) :‑
An: int
-4 int IN f(f /1)
IN(iirice
square)(2)
which evaluates to square(square(2)), that is 16. We shall see later how we could
define a polymorphic version of twice
which would not be restricted to
integer functions.
Note that a lambda expression evaluates to a closure which consists of the
declaration and body of the lambda expression together with a binding corresponding
to the environment in which the lambda expression was evaluated;
this gives values for the free variables in the body.
The reader will note the omission of assignment.
Its addition would scar.cely affect the syntax, but it would complicate
the formal semantics by requiring the notion of store. It would also
complicate the rules for type-checking, since in order to
preserve static type-checking, we would have to make sure that
types were constants, not subject to change by assignment. This
matter is discussed further in Section 3.5.
2.2. Bindings
and Declarations
An unconventional feature of Pebble is that it treats
bindings, such as x — 3, as values. They may he passed as arguments
and results of functions,
and they may be components of data structures, just like
integers or any other values. The expression x: int —3 has as its value the
binding x-3. A binding is evaluated by evaluating its right hand side and
attaching this to the variable. Thus if x is 3 in the current
environment, the expression y: int — x + I evaluates to
the binding y 4.
The expression x: int —3 may be written more briefly x :—
3; the type of 3, which is int, is supplied automatically.
The type of a binding is a declaration. Thus the
binding expression x 3 has as its type the declaration x: in Bindings may be combined
by pairing; unlike most other values, a pair of bindings is
another binding. Thus [x :— 3, b : (rue] is also a binding. After LET such a
complex binding acts as two bindings "in parallel,"
binding both x and h. Thus
LET x 0 IN LET[x :— 3, y :—x] IN [x, y]
has value [3, 0] not [3, 3], since both bindings in the
pair arc evaluated in the outer environment. Thus the pair constructor
"," is just like any other function. The type of the
binding [x 3, h true]
is (x: int)
x (h: bool)
since as usual if c',
has type 11 and e2 has
type f, then
[e,, e2] has
type I x I,. Using
pairing to combine bindings does introduce a left-to-right
ordering which is strictly unnecessary, but this
representation avoids
introducing any extra machinery.
For convenience we have a syntactic sugar for
combining bindings "in series." We write this B,; B,, which is short for [B„ LET B, IN 132]. There are
no other operations on bindings, with the possible exception of equality which
could well be provided.
Declarations occur not only
as the types of bindings but also in the context of lambda
expressions. Thus in
Ax:
int int IN + I
x: int is a declaration, and hence x: int int is a type.
In fact you may write any expression after the J. provided that
it evaluates to a type of the form d—* I where d is a declaration. To make two argument
lambda expressions we simply use a x declaration, thus
Ax: int x y: int int IN + y
which is of type int x int int, and could take [2, 3] as
an argument. This introduces a certain uniformity and flexibility
into the syntax of lambda expressions.
We may write some unconventional expressions
using bindings as values. For example,
LET b 3) IN LET b IN x
which evaluates to 3. Another example is
LET f(h: (x: int
x y: int) int)
:— LET h IN
+ y IN
f[x :— 1,
y :— 2]
which also evaluates to 3. Here/. takes as
argument not a pair of integers but a binding.
The main intended application of bindings as values is in
elucidating the concept of a parameterised module. Such a module
delivers a binding as its result; thus, a parameteriscd module is a function from bindings to bindings.
Consider a module which implements sorting, requires as parameter a function lesseq on integers, and produces
as its result functions issorted and
sort. It
could be represented by a function from bindings whose type would be
lesseq: (int x int bool)--+
(i.vsorted: (list int -4.
bool) x sort: (list int list int))
We go into this in more detail in Section 3.1.
If a module requires as its parameter a binding, say one
binding to f and
It, it
does no harm to give it a bigger but compatible one binding to f and g and h. This is often called
"inheritance" or "subclassing." So when we apply a
function to an argument which is a binding, a coercion is done on this binding
to "shrink" it down to the right shape, this shape being determined by
the declaration of the parameter of the function. For example we accept
LET Arith (lesseq: (int x int bool)—...,
add: (int x int int)— ...) IN
LET Sort Module(lesseq: (int
x int bool) --n (issorted:...xsort:...):—
... IN
Sort Module(Arith)
in which
SortModule needs
lesseq and
it gets lesseq and
add.
Since " " is a function, it also coerces a
binding; thus we accept
h: (lesseq:...)— (lesseq:...— add:... ...)
Pebble also has an anti-LET, which impoverishes the environment
instead of enriching it:
IMPORT B IN
E
evaluates
E in an environment
which contains only the bindings
in B, for
example,
IMPORT B IN
x
The value of this expression is the value of x in the
binding B, if
x is indeed bound by B. Otherwise
it has no value. This is very useful if B is a named collection of values from which we want to obtain
the one named x. If we write simply, LET B IN x, and x is missing from B, we would pick up any
x that happens to be in the current environment. The
construction in the example is sd useful that we provide the
syntactic sugar B $
x for it. Thus stack pop is
the value of pop in
the binding stack.
2.3. 7:ipes
We can now explain how Pebble handles types. R
may be helpful to begin by discriminating between some of the
different senses in which the word "type" is customarily used. We use
ADT to abbreviate "abstract data type."
Predicate type, simply
denoting a set of values. Example: bool considered as {true,
false}.
— Simple
ADT, a single predicate type with a collection of associated operations.
Example: stack with
particular operations:
push: (int x stack stack)
..., etc.
- Multiple
ADT, several predicates (zero or more) with a collection of associated
operations. Example: point and
line with
particular operations:
intersection: (line x line —n point) ..., etc.
— ADT
declaration, several predicate names with a collection of associated
operation names, each having inputs and outputs of given predicate
names. Example: predicate names point
and line with
operator names:
intersection: (line x line
—> point), etc.
The simple ADT is a special case of the multiple
ADT which offers notational and other conveniences to language
designers. For the ADT declaration we may think of a collection of
(predicate) type and procedure declarations, as opposed to
the representations of the types and the code for the operations.
Some examples of how these concepts appear in
different languages may help. The last column in Table I gives the
terminology for many sorted algebras.
In Pebble we take as our notion of type the first
of these, predicate types. Thus a type is simply a means of classifying
values. We are then able to define entities which are
simple ADTs, multiple ADTs, and ADT declarations. To do this we
make use of the notions of binding and declaration already
explained, and the notion of dependent type explained below.
There are two methods of achieving
"abstraction" or "hiding" of data type
implementations. One method is by parameterisation. If a module
![]()
![]()
![]()
![]()
takes an ADT as a parameter, when writing the body of the
module the parameter has access to the ADT declaration which
describes this parameter but not to the ADT itself. The other
method is to use a "password," chosen by the programmer of
the ADT or uniquely generated automatically, to protect
values of the abstract type. These approaches are illustrated
in Pebble in Sections 3.1 and 3.2.
Pebble treats types as values, just like integers
and other traditional values. We remove the sharp distinction between
"compile time" and "run time," allowing
evaluation (possibly symbolic) at compile time. This seems appropriate,
given that one of our main concerns is to express the linking of
modules and the checking of their interfaces in the language itself. Treating
types as values enriches the language to a degree at which we might
lose control of the phenomena, but we have adopted this approach to
get a language which can describe the facilities we find in existing languages
such as Mesa and Cedar. A similar but more conservative approach,
which maintained the traditional distinction between types and values,
was pursued by David MacQueen at Bell Labs, with some collaboration
by one of us (R.B.). Ile has recently applied these ideas to the design
of a module facility for ML (MacQueen, 1984): this is incorporated in
Standard ML (SML) (Harper. MacQueen, and Milner, 1986). The theoretical
basis for this work has been developed in (MacQueen and Sethi,
1982; MacQueen, Plotkin, and Sethi, 1984).
Allowing "type" to be a type causes
inconsistency in logic systems which use the "propositions as types"
idea, as shown by Girard (1972). However for programming languages
inconsistency does not arise and a denotational semantics can be
given using closures, a form of retract (Amadio and Longo,
1986). The language could be reformulated if desired using a type hierarchy,
but at a cost in complication.
2.4. Dependent Function Opes and Polymorphism
A function is said to be polymorphic if it can accept an
argument of more than one type; for example, an equality function
might be willing to accept either a pair of integers or a pair of
booleans. To clarify the way Pebble handles polymorphism
we should first discuss some different phenomena which may be described by this
term. We start with a distinction (due we believe to C. Strachey) between ad hoc and universal polymorphism.
Ad hoc polymorphism: the
code executed depends on the type of the argument; e.g., "print 3"
involves different code from "print 'nonsense—.
- Universal polymorphism: the same code is executed
regardless of the type of the argument, since the different
types of data have uniform
representation, e.g., reverse[1, 2, 3, 4] and reverse[true, false, false]. (We write
[...] for lists in examples.)
We have made this distinction in terms of program
execution, lacking a mathematical theory. Recently Reynolds has
offered a mathematical treatment (Reynolds, 1983).
In Pebble we take universal polymorphism as the
primitive idea. We are able to program ad hoc polymorphic functions
on this basis (see Section 3.3 on generic types). But universal
polymorphism may itself be handled in two ways: explicit parameterisation or type
inferences.
-- Explicit parameterisation: when we apply the
polymorphic function we pass an extra argument (parameter), namely the
type required to determine the particular instance of the
polymorphic function being used. For example, reverse would take an argument t which is a type, as well as
a list. If we want to apply it to a list of integers we
would supply the type int as the value of 1, writing reverse(int)[1, 2, 3, 4] and reverse(bool) [true, false,
false]. To understand the type of reverse
we need the notion of dependent type, to
be introduced later. This approach is due to Reynolds (1974)
and is used in Russell and CLU.
– Type inference: the type required to
instantiate the polymorphic function when it is applied
to a particular argument need not be supplied as a parameter. The
type-checker is able to infer it by inspecting the type of the
argument and the type of the required result. A convenient and general method
of doing this is by using unification on the type expression concerned
(Milner, 1978); this method is used in ML (Gordon, Milner, and Wadsworth,
1979). For example, we may write reverse[1,
2, 3, 4]. Following Girard (1972) we may regard these
type variables as universally quantified. The type of reverse would then be
for all t: type.list(i)--p list(t).
This form is used by MacQueen and Sethi (1982).
In Pebble we adopt the explicit parameterisation
form of universal polymorphism. This has been traditional when
considering instantiation of modules, as in CLU or Ada
generic types. To instantiate a module we must explicitly supply
the parameter types and procedures. Thus before we can use
a generic Ada package to do list processing on lists of integers, we must instantiate
it to integers. The pleasures of type inference polymorphism as in
ML seem harder to achieve at the module level; in fact one seems to get
involved with second order unification. This is an open area for research. It must
be said that explicit parameterisation makes programming in the kernel
language more tedious. However, Section 2.6 describes sugar which
automatically.'
supplies a value for the type parameter when a function is applied,
at the cost of some extra writing when it is defined.
For example, we might want to define a polymorphic
function for reversing a pair, applied thus
swap[int, bool][3, true],
which evaluates to [true, 3]. Here swap is applied to the pair of
types [int, bool] and delivers a function whose type is int x
bool bool x int. The type of swap is
what we will call a dependent type
(Girard, 1972; Demers and Donahue, 1980).
(A mild abuse of language, since it is really the result of
applying swap to
[int, bool] which is dependent, rather than the type of swap itself.) We will need two
kinds of dependent type constructor, one analogous to -+ for dealing with
functions, the other analogous to x for dealing with pairs.
We consider the former here, and deal with the latter in the next
section.
We might think naively that the type of swap would be
(type x type)—> (1, x 12 t2 x11)
but of course this is nonsense because the type variables
t, and 12
are not bound anywhere. The fact is that the type of the result depends on the values of
the arguments. Ilere
the arguments are a pair of types and t, and /2 are the
names for these values. We need a special arrow instead of to indicate
that we have a dependent type; to the left of the --n> we must declare the
variables I, and
12. So
the type of swap is actually
(I,: type x /2: type) (/, x /2
-412 xt1).
In order to have lambda abstraction be the only
name-binding mechanism, we introduce an operation D and take this as
syntactic sugar for
(I, : type x t2: type) D A B: (t,: type
x t2: type) type IN
LET B IN (1, x
12 12x11)
which evaluates to
(t,: type x /2: type) De
where c is
the closure which is the value of the A expression after the D. Thus
D is a new value constructor for dependent function types. For example,
the type of swap[int, bool] is int x bool bool
x int.
We may now define swap by
swap(t,: type x /2: type) (1, x /2
--0 12 x ti)
1.Xi: t, X X2: 12 -412 x I, IN [x2, x,]
Another example would be the list reversing function
R EC reverse(t: type —*) (list t —*
list 1)):—
Al: list t
—* list
t IN
IF I= nil
THEN / ELSE
append(reverse tail I, cons(head 1,
nil))
2.5. Dependent
Product Types
A similar phenomenon occurs with the type of pairs.
Suppose for example that the first element of a pair is to be a
type and the second element is to he a value of that type;
for example [int, 3] and [bool, false]. The type of all such pairs
may be written (I: type)
xx t. As
we did with we take its value to he t: type 0 c where c is the closure which is the
value of At: type
type IN t, and
0 is a new value constructor for dependent product types.
It is a dependent type because the
type of the second element depends on
the value of the first. Actually it is more
convenient technically to let this type include all pairs whose
first element is not just a type but a binding of a
type to 1. So
expressions of type (t: type)
xx t are
[t :— int, 3] and [t bool, false] for example.
A more realistic example might be
Automaton: type
— (input: type
x state: type
x output: type)
xx (if (input x slate state)x of (state —0 output))
Values of the type Automaton are pairs, consisting of
(i)
three types called input, slate, and output;
(ii)
a transition function, tf, and an output function, of.
By "three types called input, state, and output"
we mean a binding of types to these names.
Section 3 illustrates various ways of using dependent product
types to describe modules.
The simplest use of dependent products is illustrated by Automaton, in which
the first of the product is a type. We can also use dependent products
to provide union types. (Indeed what we call "dependent product" is
often called "disjoint union of a family of types" by logicians.)
When we use Automaton,
we are not concerned with what the types input, state, and output might be, but only with how
the functions tj and
of transform
values of these types. Sometimes, however, we may wish to
test the value of fst x and take advantage of what this tells us
about the type of snd x. For example, consider
t: type (tag:
bool xx (IF tag
THEN int ELSE real)).
If x has type t, then if x $ tag = true, snd x has type int.
Often t is
called a union or
sum type
and written int@ bool. The expressions (true, 3) and
(false,
3.14) have type t, so
that the separate injection functions commonly provided for
making union values are not needed.
We might try to write
Ax: t IN
IF x S
tag 'THEN snd
x+ 1 ELSE floor (snd x)
but this will not type-check, because the Pebble
type-checker is unable to keep track of the fact that after THEN the value
of x $
tag is
true. (To do so would be a major extension of the notion of
type-checking.) We therefore introduce an AS construct which can be
used like this:
Ax: t IN
IF x S tag THEN
(x AS true) + I ELSE floor(x AS false).
In general, if E
has type di
xx 12,
and fst El,
then E AS
El has type (LET d,
tiE, IN 12) and value snd E. However, if fst ESE,, then E AS El is undefined, and
hence the value of any expression in which this happens is
undefined. It is the programmer's responsibility to establish the precondition
(fst E= E,) before
any occurrence of E AS E,. For
the future we expect
to add exceptions to Pebble, and then a failing AS expression will have
an exception as its value instead of being undefined. (The AS device is
something of a patch, and we have since investigated some alternatives.)
Using this primitive, various kinds of sugar for unions
can be devised. As one example, we offer the following:
N,: t, Ni:
for lag: string
xx (IF tag ="N," THEN
t, ELSE...
ELSE IF tag ="N.;" THEN ti ELSE void)
and
CASE N
E OF
N, THEN
E,
1 •••
I Ark THEN
Ek
ELSE Et,
for
IF
ES tag ="N," THEN
LET N (E AS
"NI") IN E, ELSE
... ELSE
IF
ES tag="Nk" THEN
LET N (E AS
"Nk") IN
Ek ELSE E0
For example, if
T:— (one: int
P two: int x int ® ',zany: list
int);
then we can write z: T- ("two", (5, 10))), and the function
sum(
y: T int)
:‑
CASE v
OF
one THEN x
two THEN fst x+ snd x
may THEN
IF x = nil THEN 0 ELSE head x +
suni("many", tail x) ELSE error ( )
will add up the integers in its argument, so that suni(z) evaluates to 15.
This sugar is somewhat arbitrary, perhaps reflecting the
fact that a satisfactory syntax for discriminating the cases of a
union type has yet to be devised in any programming language.
2.6. Polymorphism
without Tears
Although we are able to define polymorphic functions like swap or reverse, it is irritating that we
must supply an explicit type argument at each call of the function.
Why can't we say swap[3, true]
instead of swap[int, bool][3, true]? ML accomplishes this by using unification
to infer the int and bool from the type of [3, true].
We propose that the Pebble
programmer, deprived of unification, should at least he allowed
to supply a function which calculates these parameter types
from the type of the actual argument.
Consider the
list reversing function,
which we defined thus with
parameter type t,
REC reverse(t: type)-,> (list t list t):-
Al: list
I list
t IN
IF 1= nil THEN... ELSE...
For our purposes we prefer the "uncurried"
version which takes two arguments
REC reverse((t:
type xx list t)-»
list t) :IF
I= nil
THEN... ELSE...
![]() which
is used thus reverse (int, [I,
2, 3])—we write [...] for lists in examples. We would like to write
reverse'[l, 2,
31 So in general reverse' E should
mean the same as reverse(t, E), where
t is
a type obtained by inspecting the type of E. If we write rE for the type
of E, t should
actually be list l(rE), where list-' is the
inverse of the type constructor list. (We allow ourselves to write
list -' for the lengthy name listinverse.) So reverse'[1, 2, 3]) means the
same as reverse(list-'(list
int), [1, 2, 3]), i.e., reverse(int, [I, 2, 3]). We shall call list-1
the "discovery function." It discovers the appropriate type
parameter for polymorphic reverse by
looking at the type of the actual argument. Our idea is that the
programmer should supply the discovery function as part of the type
of reverse'; then
by look‑
which
is used thus reverse (int, [I,
2, 3])—we write [...] for lists in examples. We would like to write
reverse'[l, 2,
31 So in general reverse' E should
mean the same as reverse(t, E), where
t is
a type obtained by inspecting the type of E. If we write rE for the type
of E, t should
actually be list l(rE), where list-' is the
inverse of the type constructor list. (We allow ourselves to write
list -' for the lengthy name listinverse.) So reverse'[1, 2, 3]) means the
same as reverse(list-'(list
int), [1, 2, 3]), i.e., reverse(int, [I, 2, 3]). We shall call list-1
the "discovery function." It discovers the appropriate type
parameter for polymorphic reverse by
looking at the type of the actual argument. Our idea is that the
programmer should supply the discovery function as part of the type
of reverse'; then
by look‑
ing
at the th-ie of reverse'
we can coerce the argument [1, 2, 3] to (int, [1,
2, 3]).
An alternative approach would be to not demand a
discovery function but instead use a general matcher, just as
unification is used in ML. Then t would get bound to int by
matching list t against list int. Since we have not just
types but functions from types to types we fear second order complications
in such a matcher and stick with discovery functions.
To put the discovery function into the type we need a new
type constructor "0" called "inferred
product." We write
R EC reverse' — A (t: type xx /: list t)0 list
-'--»t
IN IF... THEN... ELSE...
(very like reverse but with "0
list-'" inserted). When we write reverse" I, 2, 3] the type-checker
finds the type of [I, 2, 3], namely list int, applies the
discovery function to it, binds (t: type xx /: list t) to
(int, [I, 2, 3]), and then proceeds to evaluate the type of the
result; in due course die body is evaluated.
A more elaborate example is
compase((t, : type x t, : type x 13:
type xxf, : (t, 1)) x
./2: (I, —* 13))
® (AT: type IN( --'(fstt
T), snd( '(sndt T))))—> (I, --+ 13))
:—
Ax: t, IN
12(f, x)
Here
we have used functions fstt and sndt which extract the first and second
parts of a cross type to decompose the argument type.
An important property of the discovery function
coercion is that it does not endanger the security of the type system.
When [I, 2, 3], with type list int, is coerced to the type 1: type
xx /: list I® the
discovery function list ' is applied to list int to yield int. This
is only a guess about the type that is needed. The guess
is paired with the original expression to give (int, [I, 2, 3]),
and this expression must have type t: type xx /: list t. The
0 constructor and the discovery function play no role in
this type-check, and if the type int guessed by the discovery function
is wrong, the type-check will fail. In fact, the value of the expression
[1, 2, 3] plays no role either; only its type is important,
since the coercion is a function from the type list int to the type t: type xx /: list t, namely
N': list
int (1: type
xx /: list t)
IN(list '(list int), N')
which type-checks because list -'(list
int) = int and
(int, N') has
type
(I: type
xx 1: list t) when
N' has
type list int.
2.7. Extended types
The inferred product allows us to compute the type
argument of an application when the type involved is the result
of a type constructor such
as list or Often, however, we want to deal with abstract types. For
example, consider the declaration
List: type — (t: type xx dew: type xx
empty: t x cons: (dem x t t)
x
head: (t elem) x tail: (t 1))
We can write a different reverse, which works on these abstract lists: revcrse(L: List xx I: LS t -4, L $ I): IF
/= L $ empty THEN ELSE...
This reverse uses
L $ empty, L
$ cons, L $
head, and
L $
tail to
manipulate values of type L 1, and it works quite independently of what
particular type I. S
t happens
to be, i.e., independently of the representation of lists. In Sections
3.2-3.3 this style of programming is discussed further.
If we have LL:
List with LL S
elem= int,
then
LL $ cons(1, LL $ cons(2, LL $ cons(3, LL $
empty)))
has
type LL $
t; we
shall write it LL[1, 2,
3], to emphasize the similarity with the previous case. As
before, we would like to write reverse'
LL[ I, 2, 3] rather
than reverse(LL, LL[1, 2,
3]), but the situation is more complicated since LL is not a type. In
fact, the type of this reverse is L:
List xx
L $ t L $
t, as
we saw earlier. If we want to coerce LL[1, 2, 3] into (LL, LL[ I, 2, 3]), we have
nothing to go on except the type of LL[1,
2, 3]. We therefore must find some way to incorporate LL in the type
of LL[1, 2,
3], so we can write a discovery function that will extract it.
To accomplish this, we introduce the notion of
an extended type; such
a type can be derived from a binding whose first component
is N: I for
some type t. The
primitive xt converts a binding and its type (a declaration) to an
extended type; thus
LX xt(List,
LL)
defines a type. We make the equivalence rule that if an
expression E has
the type LL $ t (the
base type), then it also has the type xt(List, LL) (the extended type), and vice
versa. In other words, the xt constructor attaches some
values to the type LL $
t, but
it does not change the predicate which determines whether an
expression has that type.
We want LX to be the principal type of LL[1, 2, 3]. Then we can define
R EC reverse'(L: List xx I: xt(List, L)0 xtd
'(List) xt(List, L)):—
and write reverse'(LL[1, 2, 3]), obtaining another value of type LX. Here we
have used the inverse constructor xtd-I(List), with type (type -4 List); when applied to xt(List, LL) it yields LL. The xtd -1 function
is a convenient specialization of xt which maps xt(List, LL) into the pair
(List, LL), just
as x -I maps t, x
t, into
the pair (1,, 12). For
the definition of xtd I in terms of xt I,
see below or Table VII.
It is convenient to introduce a coercion from bindings
such as LL to
extended types such as LX, turning LL into xt(List,
LL). With this we never have to write xt
explicitly, but can just say
REC reverse'(L:
List xx L xtd
(List) -4> L):—
By
adding another coercion, from xt(List,
LL) to (L: List) xx
1: L, we
can simplify this further to
REC reverse'(L:
List xx 1: L -+)
L):—
The second coercion is just a specialization of the O
coercion to the discovery function xtd -'(List). More generally, it coerces an expression E of type
xt(b, d) to ((Md." d) xt(b, d), E), or simply (b, E). These two coercions are
described precisely in lines (h8-9) of the coerceF rule in Table VI.
There is one subtlety in type-checking
expressions involving extended types. The result type of LL $ cons is LLS t, not LX. Since by the equivalence
rule for extended and base types, any expression with one of these
types also has the other type, at first sight this causes no trouble. But suppose
we write reverselLL[I, 2,
3]). This is short for reverse' (LLS cons(1, ...)) This
expression does not type-check, because the argument of reverse' must have a principal type of the form xt(List, L) on which
xtd-'(List) can work to extract L.
But the principal type of LL cons( I. ...) is LL $ t, which does not have
this form; it needs to be LX, which does.
To solve this problem we introduce a primitive, written as
a postfix which elevates LL into a binding with the same value but a
different type. The type we want is
List' :— 1: type
xx dem: type
xx empty: LX x cons: (LX x dem LX)
x
This type is obtained from List by substituting LX, which is xt(List, LL), for / after the
first xx . The I primitive
is defined precisely in Table VI. Now we can write UT $ cons(/, ...), which has type LX, as desired. We have
REC reverse'(L:
List xx 1: L --»
L):—
lF = LT $ empty THEN 1
ELSE
append(reverse LT $
tail(/)), LT [Li $ head(1))))
A
very common situation in an abstract type is to have many
functions that take a value of the abstract type as their first
argument. For instance head and
tail are
such functions for the List abstraction,
push and
pop for
the Stack abstraction,
and so forth. If 1 has type LL (actually
xt(List. LL), we
can write LL j $ head(1) to
apply the proper head function.
An attrac‑
tive sugar for this is 1. head. In general, we write E. N for h j $ N(E) if E has type
xt(d, b). To
handle additional arguments, this is extended to write E,.N(E2) for
hi $ N(EI,
E2), for example, s.push(3) if s is a Stack with the
obvious push: (1 x int —* i). The programmer can think of push as an operation
on s without
worrying about just which abstraction is supplying it.
The power of this notation has been demonstrated by Simula and Smalltalk.
We can now write a final reverse' using the dot notation
R EC reverse'(L:
List xx 1:
L --o> L) :—
IF 1= L j S
empty THEN / ELSE append(reverse
!.tail, Li [1.head])
Now we have a neat function
which works for any representation of lists.
2.8. ripe-Checking
Given an expression in Pebble, we first
type-check it and then evaluate it. However, the
type-checking will involve some evaluation; for example, we
will have to evaluate subexpressions which denote types and those which
make bindings to type variables. Thus there are two distinct phases of
evaluation: evaluation during type-checking and evaluation proper to get
the result value. These both follow the same rules, but evaluation during
type-checking may make use of symbolic values at times when the actual
values are not available; this happens when we type-check a lambda expression.
For each form of expression we need
(i)
a type-checking rule with a
conclusion of the form: E has
type 1.
(ii)
an evaluation rule with a
conclusion of the form: E has
value e.
The
type-checking rule may evoke the evaluation rules on subexpressions, but the
evaluation rule should not need to invoke type-checking rules.
For example, an expression of the form LET... IN... is
type-checked using the following rules.
The type of LET B IN E is
found thus:
If the type of B
is void then it is just the type of E.
If the type of B
is N: t, then
it is the type of E in a new
environment computed thus: evaluate B and let e, be the right hand side of its value; the new
environment is the old one with N taking
type to and
value co.
If the type of B is d, x d2 then. evaluate B and let b2 be the second of its
value; now the result is the type of LET fst B IN LET b2 IN E.
If the type of B is a dependent type of the form d, 0 f then this must he
reduced to the previous di
x d2 case
by applyingfto the binding fst B to
get d2.
The type.lof a
binding of the form D— E is
the value of D if
it is void and E has
type void, or if it is N: r and
E has
type t, or
if it is di x d2 and [d, — fst E, d2 snd
E] has type d, x
d2; otherwise, if the value of D is a dependent type of the form d, 0 f then this must be reduced to
the d, x
d2 case by applying,/ to the binding (d, fst E) to get d2.
Note
that when we write d, fst E we
mean strictly the expression corresponding to d, rather than the value d,.
The type of a recursive binding R EC D— E is just the value of D, provided that a check on
the type of E succeeds.
The
type of a binding which is a pair is calculated as usual for a pair of expressions.
The value of a binding of the form D— E is as follows:
If the value of D is void then nil.
If the value of D is
N: t then
N— e where
e is
the value of E.
If the value of D is d, x d2 then the
value of (d, fst E, d2
sad E).
If
the value of D is
a dependent type then we need to reduce it to the previous case (as before).
A couple of examples may make this clearer. We give them
as informal proofs. The proofs are not taken down to the lowest level of
detail, but display the action of the rules just given.
EXAMPLE.
LET x: (int x int)— [1 -1- 1, 0] IN fst x
has type int (and value 2). To show this, we first compute
the type of the binding: x: (int x int) — [1 + 1, 0] has type x:
(int x int) because x: (int x int) has type type and x: (int x int) has
value x: (int x int) and [1 + 1, 0] has type int x int.
This is of the form N: t, so we evaluate the binding,
x: (hit x int) — [1 + 1, 0] has value x— [2,
0]. We type-check fst x in the new environment formed by adding [x:
(int x int)] and [x — [2, 0]].
In this environment
fst x has type int. This is the type of the whole expression.
Here is a second rather similar example, in which
LET introduces a type name. It shows why it is necessary to evaluate
the binding after the LET, not just type-check it. We need the appropriate
binding for any type names
which
may appear in the expression after IN. Here t in I: type — int is such a name, and we need its binding to evaluate the
rest of the expression.
EXAMPLE.
LET t: type
— int IN LET x: t — I IN x + 1
has
type int (and incidentally value 2). We first type-check the binding of the
first LET,
t: type — int has type 1: type and value t— int
In the new environment formed by adding [1: type] and [t int] we must type-check LET
x: — I IN x+ I. This has type int because
x: r 1
has type x: int and
x: t — I has value x 1 and
in the new environment
formed by adding [x: int] and [x x+ 1
has type int.
What about type-checking lambda expressions? For
expressions such as ,x: int
—*int IN x+1
this is straightforward. We can simply type-check x+ 1 in
an environment enriched by [x: int]. But we must also consider
polymorphic functions such as
At: type (t t)
IN Ax: t
IN E
We would like to know the type of x when type-checking
the body E, but
this depends on the argument supplied for t. However, we want the lambda expression
to type-check no matter what argument is supplied, since we want
it to be universally polymorphic. Otherwise we would have to type-check
it anew each time it is
given an argument, and this would be dynamic rather than static
type-checking. So we supply a dummy, symbolic value for t and use this while type-checking the rest of the
expression. That is, we type-check
Ax: t t IN
E
in an environment enriched by [r: type] and [t newconstant], where
newconstant is a symbolic value of type type, distinct from all other symbolic
values which may occur in this environment. This distinctness is
ensured by keeping
a depth counter in the environment and using it to construct
newconstant. Under this regime a function such as
At: type (t t) IN
(Ax: t 4 t IN
x)
will type-check (it has type denoted by 1: type —+> (1 t))
but
2: type (t 1) IN
(Ax: t t IN
x+ I)
will
fail to type-check because it makes sense only if r is int.
Thus it is necessary that at type-checking time
evaluation can give a symbolic result, since we may come across
newconstant. How do we apply a function to such a value?
We introduce a value constructing operator ! to permit the
application of a function to a symbolic argument. So if e is symbolic the result of
applying f to
e is just J! e. Similarly, if f is symbolic the result
of applying f to
e is just f! e. This enables us to do
symbolic evaluation at compile time and to compare types as
symbolic values.
There arc no operations on types except the
constructors and their inverses. Thus there is no way
to compute an integer, say, from a type. Assuming that the result of a
run-time computation is an integer or boolcan, or structure
thereof, rather than a type, there is no need to carry types around at
run time, and, for example, the pair [int, 3] can be represented at run time
simply by 3. (An exception is "extended types" (Section 2.6) which
are bindings acting as types.) Thus in Pebble, types act as
values at compile time, but although we may formally think of them as values at
run time they play no computational role.
Since our language has
dependent types, an expression can have more than one type. For
example (i :— int, 3) has type t: type x int, but it also
has the dependent type t: type
xx t. The former, called the "principal
type," is calculated by the type-checking
algorithm. To type-check
(A(t:
type xx :—
int, 3) we need an algorithm to verify that
(I :—
int, 3) has type t: type xx L
We must admit that, although our type-checker is
precisely defined by our operational semantics, we have no good
mathematical characterisation of when it will succeed. We
could have made it weaker and probably easier to characterise,
by restricting the amount of symbolic evaluation carried out
at compile time, but this would not necessarily help the programmer. We
would welcome suggestions for characterisation.
3, APPLICATIONS
This section presents a number of applications of
Pebble, mainly to programming in the large: interlaces and
implementations, and abstract data types. We also give
treatments of generic types, union types, recursive types
such as list, and assignment. The point is to sec how all these facilities can
be provided simply in Pebble.
3.1. Interfaces
and Implementations
The most important recent development in programming
languages is the introduction of an explicit notion of interface to stand between the
implementation of an abstraction and its clients. To paraphrase Parnas:
– An interface is the set of
assumptions that a programmer needs to make about another program
in order to show the correctness of his program.
Sometimes an interface is called a specification (e.g., in Ada, where the term
is package specification). We
will call the other program an implementation of the interface, and the
program which depends on the interface the client.
In a practical present day language, it is not
possible to check automatically that the interface assumptions are
strong enough to make the client program correct, or that an
implementation actually satisfies the assumptions. In fact,
existing languages cannot even express all the assumptions that
may be needed. They are confined to specifying the names
and types of the procedures and other values in the interface.
This is exactly the function of a definition
module in Mesa or Modula2, a package specification in Ada, or a module type
in Euclid. These names and types are the assumptions which the client
may make, and which the implementation must satisfy by providing values of
the proper types. In one of these languages we might define an
interface for a real number abstraction as follows:
interface Real;
type real;
function plus(x: real; y: real): real;
end
and
an implementation of this interface, using an existing type float, might look like this:
implementation Reall4
implements Real;
type real
=float;
function
plus(x: real; y: real): real; begin
if
... then ... else ... end;
return
...;
end;
end
In Pebble an interface such as Real is simply a
declaration for a type
Real S real land
various functions such as plus; an
implementation of Real is
a binding whose type is Real. Here is the interface:
Real: type - (real: type
xx
plus: (real
x real real)
x ...);
Note
that this is a dependent type: the type of Real S plus
depends on the value of Real S real.
Now for the implementation, a binding with type Real. It gives real the value
float, which must denote some already-existing type, and it has an explicit
A-expression for plus.
RealFl: Real [real
:- float;
plus :- Ax: real x y: real -> real IN
(IF ... THEN ... ELSE ...), ...]
On this foundation we can define another interface Complex, with a declaration
for a mod function
which takes a Complex S complex to
a RealFl S real,
Complex: type - (complex: type xx
mod: complex -4 RealFl S
real x
...)
If we do not wish to commit ourselves to the RealFl implementation, we can
define a pararneterised interface MakeComplex,
which takes a Real
para
meter:
MakeComplex(R: Real -> type)
(complex: type xx
mod: complex -4 R S real x ...)
Then the previous Complex can be defined by Complex: type ti MakeComplex(RealFl) Real Fl)
This illustrates the point that a module is usually a
function producing some declaration or binding (the one it defines)
from other declarations and bindings (the interfaces and implementations
it depends on).
Now the familiar cartesian and polar
implementations of complex numbers can be defined, still with a Real
parameter.
This is possible because the implementations
depend on real numbers only through the elements of a binding with type Real: the real type, the plus function, etc.
A-fakeCartesian(R:
Real -4> MakeComplex(R)):-
[complex :- R
S real
x R
S real;
mod :- fie: complex R S real
IN R S
sqrt((fst c)2 + (snd 02), -.1;
Make Polar(R: Real -->> MakeComplex(R))
:‑
[complex R
S real
x R
S real;
mod Ac:
complex -> R S real IN fst c,...];
These are functions which, given an implementation of Real, will yield an implementation
of MakeComplex(Real). To
get actual implementations of Complex
(which is MakeComplex(RealFI)),
we apply these functions:
Carte.vian: Complex
— MakeCartesian(Rea1F1)
Polar: Complex
— MakePolar(RealFI);
If
we do not need the flexibility of different kinds of complex number, we can
dispense with the Make functions
and simply write
Cartesian: Complex
— [complex R x R;
mod
:— Ac: complex —+ R IN
Realn S
syri((fst c)2 + (snd
c)2), ...],
Polar: Complex " [complex R x R;
mod :— Ac: complex R IN
fst c, ...]
WHERE R:—
Rea1F1S real
To show how far this can be pushed, we define an interface
Transform which
deals with real numbers and two implementations of complex numbers.
Among other things, it includes a map
function which takes one of each
kind of complex into a real,
Trams" Om( R: Real xx
CI: MakeComplex(R) x
C2: MakeComplex(R)—, type)
:— (map: (CI $ complex x
C2 $ complex R $ real) x...);
Note that this declaration requires Cl and C2 to be based on the same implementation
of Real. An
implementation of this interface would look like
Transform(' P: Transform (RealFI,
Cartesian, Polar)
[map
:— AC I: Cartesian $ complex x C2: Polar $ complex --+
Reallq $ real
IN IF...THEN ...ELSE...,...];
Thus in Pebble it is easy to obtain any desired degree of
flexibility in defining interfaces and implementations. In most
applications, the amount of parameterization shown in
these examples is not necessary, and definitions like the simpler ones for Cartesian
and Polar
would be
used.
We leave it as an exercise for the reader to recast the
module facilities of Ada, CIA), Euclid, and Mesa in the forms of
Pebble.
3.2. Abstract
Data Types
An abstract
data type glues some operations to a type, e.g., a stack
with push, pop, top, etc.
Clients of the abstraction are not allowed to depend on the
value of the type (e.g., whether a stack is represented as a list or an
array), or on the actual implementations of the
operations. In Pebble
terms, the abstract type is a declaration, and the client
takes an implementation as a parameter. Thus
|
intStackDecl: type — |
(stk: type xx empty: sik x isE4pty: (sik bool) x push: (int x stk sik) x top: (sik int) x ...) |
is an abstract data type for a stack of ints. We have
used a dependent xx type to express the fact that the operations work
on values of type stk which
is also part of the abstraction. We could instead have given a parameterized
declaration for the operations
intStackOpsDecl(stk: type
type) :—
(empty:
stk x
isEmpty: (sik —n bool) x push: (int x stk stk) x top: stk —0 int) x ...)
Matters are somewhat complicated by the fact that the
abstraction may itself he parameterized. We would probably prefer
a stock abstraction,
for example, that is not committed to the type of value being
stacked. This gives us still more choices about how to arrange
things. To illustrate some of the possibilities, we give definitions for the
smallest reasonable pieces of a stack abstraction, and show
various of putting them together.
We begin with a function producing a declaration
for the stack operations; it has both the element type elem and
the stack type sik as
parameters:
stackOpsDecl(elem: type
x sik: type
type) :—
(empty:
sik x
isEmpty: (stk bool)
x
push: (ele4 x stk sik) x
lop: (stk —0 elem) x ...)
With
this we can write the previous definition of MtStackOpsDecl more concisely as
intStackOpsDecl(stk: type
type) :— StackOpsDecl[int„stk]
The
type of a conventional stack abstraction, parameterized by the element type,
is a function that produces a declaration for a dependent type:
StackDecl(ele4: type type) :— stk: type xx StackOpsDecl[elem, stk]
and we
can write the previous intStackDecl as intStackDecktypc— StackDecl int
Leaving
the clement type unbound; we can write an implementation of StackDecl using lists to represent
stacks,
 StackFromList(el: type
-+ StackDecl el) :—
StackFromList(el: type
-+ StackDecl el) :—
[stk list el;
empty :— nil; isEmpty(s:stk boo!) : .]
WHERE list: type
-+ type —
Here
we have given the type of list but
omitted the implementation, which is likely to be
primitive. Then we can apply this to int, getting
IntStackFromList: IntStackDecl StackfromList
int
By analogy with list, if we have only one implementation of stacks to
deal with we will probably just call it stack rather than StackFromList. In particular,
an ordinary client will probably only use one implementation, and
will be written
Client(stack:
(el: type StackDecl el) ...) :‑
LET
intStack :— stack int
IN
-Client body‑
This arrangement for the implementation leaves something
to be desired in security.
Consider for simplicity the case where we use only integer
lists,
LET Client(stack:
IntStackDecl) :— -Client body‑
IN Client(IntStackFronzList)...
comment Main Program;
For example,
Client(stack: IntStackDecl):— (stack;
push2(n,
s)
stack S
push(n, stack S
push(n, s))) IN
LET Stack2 Client(hnStackFramList)
IN Stack2 S push2(3, stack2 S
empty))
The client body is type-checked without any knowledge of the representation
of stack, so
replacing stack S
push by
cons would cause a type error. But the Main Program can
construct a list int and pass it off as a stack2 S stack,
so replacing stack2
S empty by nil would not cause a type error.
Any list is an acceptable representation of stacks, but if we had chosen
an array with a counter, then passing off an array with a negative
counter would cause disaster. To defend itself against
such forgeries, an implementation such as StackFromList may need a way to
protect the ability to construct a stk value. To this end we introduce the primitive
Abstract Type: (T: type x p:
password —»
AT: type
xx ohs: (T4AT) x rep: (AT 7))— ...;
This function returns a new type AT, together with functions abs and rep which map back and forth
between AT and
the parameter type T. Values
of type AT can
be constructed only by the abs function
returned by a call of Abstract
Type with the same Password.
Other languages with a similar protection
mechanism (for example ML) do not use a password, but instead make AbstraciType non-applicative, so
that it returns a different AT each time it is called.
This is equivalent to making up a new password automatically each time
you recompile. This ensures that no intruder can invoke Abstract Type on his own and get
hold of the abs function.
We have not used this approach for two reasons. First, a
non-applicative Abst•actType
does not lit easily into the formal operational
semantics for Pebble. Both the intuitive notion of type-checking
described in Section 2 and the formal one in Section 5 depend on the fact that
identical expressions in
the same environment have the same value,
i.e., that all functions are applicative. The use of a password to make an
abstract type unique is quite compatible with this approach.
Second, in a system with persistent data,
automatic password generation on compilation does not make
sense. The implementor might change the implementation of stack to make it more efficient
without changing the representation. She would not want this to
invalidate all existing stack values.
So the new version would use the old password. Instead we think of converting a
value v to an abstract value abs(v)
as a way of asserting some invariant that
involves V. The implementations of
operations on abs(v) depend
on this invariant for their correctness. The implementer is responsible
for ensuring that the invariant does in fact hold for any v in an expression
abs(v); he
does this by
·
checking that each application of abs in his code satisfies a
suitable pre-condition;
·
preventing any use of abs outside his code, so that every
application is checked.
A natural way to identify the implementer is by
his knowledge of a suitable password. This requires no extensions to
the language, and the only assumption it requires about the programming
system is that other programmers do not have access to the password in
the text of the implementation.
Using AbstractON
we can write a secure implementation:
StackFromList(el: type
-4> StackDecl el) :—
LET (st :— a
16 AT, abs a abs, rep a $ rep) WHERE a :— Abstract Type(list el, "PASSWORDXYZ")) IN
(stk st;
empty abs nil;
isEmpty(s: stk bool):—
(rep s) = nil;
...)
Here
we are also showing how to rename the values produced by Abstract Type; if the names
provided by its declaration are satisfactory, we could simply write
•S'taekFrontList(el: type Stack
Deel el) :— LET AbstractType(list
el,
"PASSWORDXYZ") IN
(stk :—
AT;
empty —
abs nil;
isEmpti(.s: stk bool):— (rep s) = nil;
•••)
The
abs. and
rep functions
are not returned from this StackFromList,
and because of the password, there is no way to make
a type equal to the AT which
is returned. Hence the program outside the implementation has no way
to forge or inspect AT values.
Sometimes it is convenient
to include the element type in the abstraction:
aStackDecl: type
— elem: type
xx
stk: type xx
StackOpsDeel[elem, stk]
This
allows polymorphic stack-bashing functions to be written more neatly. An
aStackDecl value
is a binding. For example, redefining intStack,
OttStack: aStackDecl (ekm :— int,
Stack FromList int) An example of such a
polymorphic function is
Reversc(S: aStackDecl xx x: S Sstk
—*) S $ sac) :— LET
S IN
LET rev(
y: sik x z:
stk --• stk)
:—
IF
isEmpty y THEN
z
ELSE rev(pop
y, push(top y. z)) IN rev(x,
empty)
so that Reverse(intStack, intStack $ MakeStack[1, 2,
3] = intStack $ MakeStack [3, 2, I ]).
3.3. Generic 7j'pes
A generic ope glues
a value to an instance of an abstract data type. Thus, for example, we might
want a generic type called atom, such
that each value carries with it a procedure for printing it. A typical
atom value
might
be
[string, string $ Print, "Hello"]
A simple way to get this effect (using < ) for string
concatenation) is
A unnOps(i: type
-4 type)
:— Print: (t -4 list char);
(thmiT: type I. type xx
A
tomOps(t);
atom: type — at:
atomT xx
pal:
al S
Print A ton(a: atom list char) :— a $ Print(a $ va!);
REC
PrintList(1: list aim?: list
char) :‑
IF
null / THEN "[
ELSE "[" < > Print A tom(hcad 1) < > "," <> Prim List(tail <
"]"
With this we can write
stringAtomT: atomT — [string,
Print String]; hello: atom — [string A tomT, "Hello"];
int A tomT: atomT — [int,
Printhtt];
three: atom — [int A toniT, 3]
Then Printil
tom three = "3", and
Print List[hello, three, nil] =
"[Hello, [3, [
If
int and string are extended types (see Section 2.6) with Print procedures, so that xtd (atomT) succeeds, then we could
define atom
differently:
atom: type
— at: atoniT xx ral: at $ I Qx (xtd atontT)
Now
we can write Print A tom( 3),
and 3 will be coerced into ((r — int $ Print int $ Print),
3) by the coercion for 10 types, because shrinkF(type, atomT)(int) evaluates to (I— int t, Print — int $ Print).
This is line for dealing with an individual
value which can be turned into a atom, but suppose we want
to print a list of infs. It is not attractive to first construct a
list of atoms; we would like to do this on the fly. This observation
leads to different Print functions,
using the same definition of
atom.
The idea is to package a type t, and
a function for turning i's into atoms,
atomX 1: type xx cony: (1 atom)
Print/ atomX xx
v: at S list char) :‑
LET
a :– at 8 corny v IN a S Print(a S vu!)
R
EC Printlist(at: atomX xx I: list at S I --• list
char) :‑
IF
null I THEN "[ ]"
ELSE "[" < > Print Atom[at, head 1]
< > "," < > Printlist[at, tail
1] <> "1" intAsAtom: atomX (t :– int,
conv(v: 1 --0 atom):–
(t :– int, Print :– PrintInt, val v))
3.4. Recursive Types
Pebble handles recursive functions in the
standard operational style, relying on the fact that a A-expression evaluates
to a closure in which evaluates of the body is deferred. The language has types
which involve closures, namely the dependent types constructed
with -4> and xx , and it turns out that the operational semantics can
handle recursive type definitions involving these constructors. A
simple example is
LET R EC IntList: type – head: int xx tail:
(I: IntList (f)v: void)
where for simplicity we have confined ourselves to lists
of integers rather than introducing a type parameter. Although the
evaluation rules for recursion were not designed to handle this kind of
expression, they in fact do so quite well. Note that ® has
the necessary xx built in.
3.5. Assignment
Although Pebble as we have presented it is entirely
applicative, it would be possible to introduce imperative primitives.
For example, we could add
var:
type —> type
Then var int is the type of a variable whose contents is
an int. We also need
new:
(T: type —» var T)x
MakeAssign: (T: type –» (var Tx T void )) x MakeDereference:
(T: type –» (var T T))
From MakeAssign and MakeDereference we can construct and I
procedures for any type.
Of course, these arc only declarations, and the
implementation will necessarily be by primitives. Furthermore, the
semantics given in this paper
would have to be modified to carry around a store which :=
and j can use to communicate.
In addition, steps would have to be taken to preserve the
soundness of the type-checking in the presence of these
non-applicative functions. The simplest way to do this is
to divide the function types into pure
or applicative versus impure or imperative ones. MakeAssign and MakeDereference return impure
functions, as does any function defined by a A-expression
whose body contains an application of an impure function. Then an impure
symbolic value is one that contains an application of an impure
function. We can never infer that such a value is equal to any other value,
even one with an identical form.(at least not without a more powerful
reasoning system than the one in the Pebble formal semantics).
4. VALUES AND SYNTAX
This section gives a formal description of the
values and syntax of Pebble. It also defines a relation "has
type" (written :::) between values
and types; in other words, it specifics the set of values
corresponding to each type. Note that these sets are not disjoint.
Section 5 gives a formal description of the semantics of Pebble, and
defines a relation "has type" (written ::) between expressions and types.
4.1. Values
We start our description of Pebble with a
definition of the space of values. These may be partitioned into subsets, such
as function values, pairs, and types. Some of these may be further
partitioned into more refined subsets, such as cross types and arrow
types. Our values are the kind of values which would be handled by a
compiler or an interpreter, rather than the ones which
would be used in giving a traditional denotational semantics for
our language. The main difference is that we represent functions
by closures instead of by the partial functions and functionals
of denotational semantics. Table II gives a complete breakdown of the set of
values.
All these value constructors except
"," "!" ":", closure
and fix could be replaced by constants using
"!" and ",". Thus, for example, 1 x t could become x ! (t,
1).
Each
set of values, denoted by a lowercase letter, is composed of the sets written
immediately to the right of it, e.g.,
e = eou f (e,
e)u butt.) (f! e)
where by (e, e) we mean the set of all
values (v1,
v2)
such that vl
E e and
v2
E e. Similarly
nil means {nil}, (f ! e) means
{ (ui! v2)I
v, e f, v2 e
e}, and
so on for each value constructing operator. The primitive
constants of the value space and constructors such as closure arc
written in this font throughout
this section. Meta-variables which denote values or sets of values,
possibly of a given kind, are single lowercase letters in this font, possibly
subscriptcd.
We now examine each kind of
value in turn, giving a brief informal explanation. Indented
paragraphs describe how a set of values may be partitioned into
disjoint subsets.
– e is the set of all values,
everything which may be denoted by an expression.
– e, consists of the primitive
values true, false, 0,
I, all
except the
functions and types.
– f consists
of the values which are functions, as follows.
* The values in which are
primitives such as addition or mul‑
tiplication of integers. They include the functions x, -4,
typeOf on types;
the inverse functions x 0 I, 0 and the functions
if, fst, snd, rlis on values. Note that there are no other
operations on types,
TABLE II
Values
![]() e co viz true, false,
0, 1, 2, ..., etc.
e co viz true, false,
0, 1, 2, ..., etc.
fo viz. + , x, etc.
closure(p,
d, E)
nil
[e, c]
n
e nil
[b, b]
fix(ff)
t„ viz, boot,
int, etc. void
x
'of
r
d f
Of
n: r
void d x d
d 0 f
del
![]() f!e
f!e
declarations, or bindings. In particular, there is no
equality. This is important if we wish to avoid the need for run-time
representations of these things.
* closure
values, the results of evaluating A-expressions. A closure is composed of:
1. an
environment p, which
associates a type and a value with each name;
2. a
declaration value,
which gives the bound variables of the A-cxpresssion;
3. a body expression,
which is the expression following IN in the
A-expression (expressions are defined in Section 4.2).
-
nil, the 0-tuple.
- [e, e], the 2-tuples (ordered pairs)
of values. The pair forming operation is ".".
In general we use brackets for pairs, as in [I, [2. [3, nil]]];
formally, brackets are just a syntactic variant of
parentheses. Since "," associates to the right, we can
also write [1, 2, 3, nil].
- binding values, which associate
names with values. For example, evaluating LET x: int —1 + 2
IN ... will produce a binding x-3 which associates x with 3.
Strictly we should discriminate between "binding expressions"
and "binding values," but mostly we will be sloppy and say "binding"
for either. Bindings are either elementary or tuples, thus:
* N e, which binds a single name N to a value e.
* nil.
The 0-tuple is also a binding.
* [b, b], which is a pair of bindings,
is also a binding. The binding [b,,
h,] binds the variables of b, and those of h2. This is a special
case of [e, e] above, since h is a subset of e.
* fix
values, which result from the evaluation of recursive bindings. A
fix value contains the function which represents one step of the recursive definition
(roughly, the functional whose fixed point is being computed). Details
are given in Section 5.2.5.
-
type values,
consisting of:
* t„, some built-in types such as
hooleans (bool) and integers (int). They include the type type
which is the type of all type expressions.
* void,
the type of nil.
* t x I, which is the type of pairs.
If expression E, has
type t, and
expression E2 has type 12, then the pair [E,, E2] has
type I, x
t2.
*t0fa dependent version of t x 1. This
is explained in Section 2.5.
* f t, which
is the type of functions.
* d N f a dependent version of t t.
This is explained in
Section
2.4.
*
(Of the inferred product type. This is explained
in Section 2.6.
·
d, declarations.
These are the type of bindings; for example, the type of x: int - 1
+2 is x: int. They
give types for the three kinds of bindings above.
-
N: 1, a
basic declaration, which associates name N with type I,
e.g., x: int.
-
void, the type of the nil binding.
-
d x d, the type of a pair of bindings (a special
case of t x t).
-
d 0 f, a dependent version of d x d.
-
d® f, the inferred
product type.
- f! e is
the application of the primitive function or symbolic value f to the value e. Such applications are values
which may be simplified.
To
formulate a soundness theorem we may define a relation between
values and types, analogous to the :: ("has
type") relation between expressions and types
defined in Section 5. Unlike the latter, it is independent
of any environment. We could define it by operational semantic rules, but
it is shorter to give the following informal inductive definition. In one
or two places we need the ("has value") relation
between expressions and values defined in Section 5. We first define
a subsidiary function typeOf from declaration values to
type values; for example, typeOf(x: int)= int and typeOf(x: int x
p: !mol)=
int x bool,
typeOf(void) = void
typeOf(N: t)= t
typeOf(d1 x d2) = typeOf(di)
x typeOf(d2).
(The cases for 0 and 0 are given in Table VI.)
We also need a notion of applying a funcion value
f to
an argument
-
value e, to
obtain a result value e; this
is written J! e, e and
is defined
precisely in Section 5. For example, +! (3, 4)--, 7.
Now for the definition of ::: which relates values and
types,
-
true ::: bool, false ::: bool, 0 ::: int, I :::
int, and so on. not ::: bool bool, and so on for other operators.
x ::: type x type -n
type,
-• ::: type x type type.
closni-e(p,
d, E) 1, -412 if
I, = typeOf
d and for all bindings b such
that b d we have p[d— b] E (2.
- nil ::: void.
e1,
e2:::1,
x 12 if
e, t, and
e2:::
12.
- N e N :t if
e 1.
fix(f,f) cl if f d d.
- bool
::: type, int ::: type, type ::: type, void ::: type.
t, x /2 ::: type
if r, ::: type and 12 ::: type.
- N :1 ::: type if 1::: type. d
0 f type
if f d type.
(II> f ::: type
if f d type.
t, 12 ::: type
if t, ::: type and 12 ::: type.
f! e ::: '2
if e and f t /2.
- e,, e2 1, 0 f if there is some 12 such that f! el —412 and
(e 1 , e2)
::: /I X t2.
e:::(0f if e t.
f, f if
for all e„ such
that e0 ::: 5, there
is some 12
such that
f! e„ -4 (2 and
ft! eo--4e and
e (2.
Now
if e, we would like to have e 1 if E:: t (soundness);
we hope
TABLE III
Syntax
![]()
|
Type T bool 7', x T2 T„ D To x D2 D, xx Di F® type |
Introduction |
Elimination |
|
E2 F A 7' IN E Primitives B D E REC
D E, D E B,, 82 B,; B2 N:—
E N(T): all types in the left column N |
IF ETIIEN El ELSE E2 fst
E snd E F, AS F2 FE LET II IN E IMPORT BIN E typeOf D |
![]() Note. Either round or square brackets may be used for grouping. All the
operators associate to
the right. Precedence is: lowest IN, then "," ";", then —, then —. then x xx, then: highest application.
Note. Either round or square brackets may be used for grouping. All the
operators associate to
the right. Precedence is: lowest IN, then "," ";", then —, then —. then x xx, then: highest application.
this is provable. But our type-checking rules, which use
symbolic evaluation, cannot always achieve E:: t if
e t (completeness).
A closure may have a certain type for all bindings, but symbolic
evaluation may fail to show this. Consider for example
(2x: int (IF x<x
+ I THEN int ELSE boot) IN x) :: int int
This is not derivable from our type-checking rules because
symbolic evaluation cannot show that x<x+ I for an arbitrary
integer x. But the latter is true, so if f is the value of
the lambda expression we do get
f int
by the definition above for closures. This limitation does not seem
to present a major practical obstacle, but the matter would repay further
study.
4.2. Syntax
We can give the syntax
of Pebble in traditional BNF form, but there will be
only three syntax classes: name (N), number (1), and expression (E),
N ::= letter(letter I digit)*
1 ::= digit digit*
E ::= E -4> N : El Exx EI[E, Ell
,lEIN El N(E) :—EIFIX El REC E— EIN EI
EIES
NI E.N INI IMPORT E IN E
IIFE TH EN E ELSE El E AS
E IE El LET
E IN
E I(E)I
[E].
It is more helpful to divide the expressions up
according to the type of value they produce. We distinguish subsets of the set E of all expressions
thus: T for
types, D for
declarations, B for
bindings, and F for
functions. These cannot be distinguished syntactically since an operator/operand
expression of the form E E could denote any of these,
as could a name used as a variable. However, it makes more sense if
we write, for example, LET B IN E instead of LET E IN E, showing that LET requires an
expression whose value is a binding.
TABLE
IV
Summary of Abbreviations
![]() Non-terminal Must evaluate to Example
Non-terminal Must evaluate to Example
![]() N Name
N Name
E Expression gal(i,
3) + I
T Type int
D Declaration i:
int
13 Binding i:
int — 3
F Function bool IN
i > 3
![]() All the
non-terminals except N are syntactically equivalent to E.
All the
non-terminals except N are syntactically equivalent to E.
|
|
|
5 <-4 LL.1 |
n••-n |
LLI -a M 11) U *".X III ? (-1 W/ W t Z • -7 C .* •-
[LI " I2 t zx t x -6 ·E 0 - ," 2- 11.1 Q. Q. |
|||
|
|
|
|
|
|
0., CI. a- ra a V., o
li |
iv kr
? ? |
|
|
LO |
tw ti) |
|
|
|
e.) |
O 4 z '- |
— A |
|
|
|
0 Lt. |
|
|
71 a 03 |
I-7: E: i:C1 eq Z Z F. |
7.. et/ A -a |
|
|
|
|
,... |
.1. |
..... A Z |
1_, W /13 io eo ....1 .. H F." 4 Z 1 1.4 w - _ _ .._) ._) • o c;) 45 |
CL1 41 -0 >-. `'' 2 ·- D. ' ----::: |
|
|
|
|
A |
- |
-,-.. * |
Z Z '--“--' x Z |
d. Lg - . |
3) . . • __ Q.
-t, iv °a. 0:,'
. • .- ›-, -• : 1-.. - —
,-. x ' . • -.-
.F. > i- z Z T T )( .n
6v
0 'L-'' 44 44 0-1 '-' •-• t , , Opp rzT ,- ? 4- .-
6. 14 z
-I Di' '1'1 - .
• - .. 1-.7 .7-..
-z.
t:J- 7;
F-- ii H ';' K 4'
?" erl ‘ 'L 7 7
i ., t 5 t 0
i m:.. '.2. :21 .'-. 7,. ;;
.- - t cl 2 0-, I- A 0 .5". U -c; -c;
..-2.*...c4cLi-L.'-14Q(Zir-, L4j F'F'
42` r
•
u4 : Li-
- I
i cq L-LT
_!. L1.1 r E-:
:r. ki 41 Ix —
10 i
1.z r' ILI y
F--• F-- 6
co x x
+ :-.
C. 'Z' v; 3 f x '–' ,,
·-
z.. cc -- al ua O o C24 c4
It is also helpful to organise the syntax
according to types and to the introduction and elimination
rules for expressions of each type. This is a common format in
recent work on logic. For example, a value of type T, x "2 is
introduced by an expression of the form E1, E2; it
is eliminated by expressions of the form fst E or snd E.
The syntax presented in this
way is shown in Table Ill: a list of the notations used is given in
Table IV. Table V shows some abbreviations which make Pebble
more readable, for example eliminating the A notation for
function definitions in traditional style.
5. OPERATIONAL
SEMANTICS
We have a precise operational semantics for
Pebble, in the form of the set of inference rules in Table VI. This section
gives the notation for the inference rules, explains why they yield at most
one value for an expression, and discusses the way in
which values can be converted into expressions and fed hack
through the inference system. Then we explain in detail how each
rule works.
TABLE Vla
Inference
Rules for Introduction
![]()
|
Rule .1')Pc x I void x T2 |
|
Introduction |
|
|
(I) Et :: t,, E2 t, |
|
||
|
|
|
|
|
![]() (0) :> t, x 12 c2i
(0) :> t, x 12 c2i
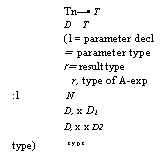 (I) (T, t; :t typcOrd Ito. to—ft=
II
(I) (T, t; :t typcOrd Ito. to—ft=
II
(2)
or Titi,t,--tdC>f,linewc(n+1)—,t),
(3) p(depth)= n, //depth =n
+ I j =p'
(4) p' 1—
LET ncwc(n + 1),d
IN E
![]() (0) (A T, IN E) :> t, .closurc(p% d, E) (I) F:: t, fixtype(t)—+ t' d d
(0) (A T, IN E) :> t, .closurc(p% d, E) (I) F:: t, fixtype(t)—+ t' d d
![]() (0) FIX F::d fix(f,f)
(0) FIX F::d fix(f,f)
T :: type
![]()
![]() (0) N:T:> type t
(0) N:T:> type t
(I) p(N)::-.1--e0,e0
![]() (0) N:> te
(0) N:> te
ft ft 11 0
A AAA
W w w 1
.0
![]() S .1? F. II P-1
S .1? F. II P-1
zz-J
o.
![]() an
an
|
·0 pC |
rt ;I W O II ti Lsa |
A |
tla -ct 11 --0 |
|
; |
A 4,74 |
||
|
|
|
1.1 |
|
|
|
I ral |
0 |
t |
|
|
|
. |
la7 |
.21'1? |
|
|
.2 |
|
|
|
.... |
ft |
|
8 A |
A |
7; |
|
|
|
|
0 |
|
|
A o |
; 1.17 |
'97 _• • 4 |
x – *T:3 |
_– |
|
|
: : |
II |
|
|
|
Pt:t at |
III |
t:q |
|
|
LLT |
|
|
|
|
O |
O |
0 |
|
|
|
N O |
("4 6•1 u 0. |
·-nN |
Pel |
|
||
|
|
|
|
d.) |
|
|
|
||
|
|
|
|
E E |
|
|
|
||
|
|
|
|
–=-• |
|
|
|
||
|
F. 79. |
|
|
. kTil |
|
x |
|
||
|
x |
|
|
|
|
|
|
||

![]()
![]()
![]()
![]()
![]() 0 8.
0 8.
A
O
y.
|
A n I. 0 N |
114 I. 0 M |
11.1 I. 0 "7 |
0 |
A O |
7
LL

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()


![]()
![]()
![]()
|
|
|
|
|
|
|
|||||||||
|
|
|
ft z z z a |
|
|
||||||||||
|
|
|
|
|
|||||||||||
|
|
|
|
||||||||||||
|
X |
|
|
||||||||||||
|
|
|
|
|
|
|
|||||||||
|
|
|
8 z |
|
|
• |
|
|
|
|
|||||
|
47; |
=c) |
k k'-'6 " |
|
|
|
|
T II
E |
|
|
|||||
|
at. ;:4 |
-0 |
Z.
'7. |
1-* al |
|
& |
|
3 |
|
|
|||||
|
'eT |
T 7, |
k -F. "' 8 -) 1 t z cx. z . z |
z |
11.1
0 |
ft z z |
Lt. |
LS o).7. g T n. a, |
U |
|
|||||

![]() I 1. ?i a I fi
I 1. ?i a I fi
cf. ct: 1,=,
(1-
; O
TA:-:®Et
|
a a 00 ^00 |
nanana:a II —————— 0 0 0 0 0 0 0 CI 141 00 |
anon 1:1 -0 -0 -0 8 '8 "8 N 71. |
P |
a ip 0 M |
5.1. Inference Rule Semantics
The basic idea, which we derive from Plotkin, is
to specify an operational semantics by means of a set of
inference rules. The operations of evaluation are the steps
in a proof that uses the rules. The advantage of this approach is that the
control mechanism of the evaluator does not need to he written
down, since it is implicit in the well-known algorithm for deriving a proof.
Indeed, our rules can be trivially translated into Prolog, and
then can be run to give a working evaluator. This has been done by Glen
Stone, a student at Manchester University, for a slightly different version
of the rules.
In general, of course, this will lead to a
non-deterministic and inefficient evaluator; the particular
rules we use, however, allow an efficient deterministic evaluator
to be easily derived.
5.1.1.
Notation. Each rule has a set of premises assertioni, assertion„
and a conclusion assertion„, written thus:
assertion„ assertion„
![]() assertion()
assertion()
As usual, the meaning is that if each of the
premises is established, then the conclusion is also
established. We write
assertion , „ assertion,„,
or assertionn, assertion2„2
![]() assertion°
assertion°
as an abbreviation for the two rules
assertion ..., assertion,,,, assertion21, assertion2„2
assertion° assertion°
Note that or has lower precedence than
",". Sometimes or is more deeply nested, in which case the meaning is
to convert the premises to disjunctive normal form, and then apply
this expansion.
An
assertion is
environment I— simple assertion.
An environment
is a function mapping a hame to a type and a value. The
environment for the conclusion is always denoted by p, and is not written explicitly.
If the environment for a premise is also p (as it nearly always is), it
is also omitted.
A simple
assertion is one of the following.
(la) E:: t asserts that E has type t in the given
environment.
(l b) E:>
t asserts that E
has principal type t in the given environ‑
ment.
(2)
e asserts
that E has
value e in the
given environment.
(3)
e :::-,format
asserts that e
is of the form given by format, i.e., that after
each variable in format is replaced by some sequence of symbols, the resulting
sequence of symbols is identical to e.
Every occurrence of a variable in a rule
must be instantiated in the same way. For example,
-* here 1,-4i2 is
a format, with variables t, and 12. If e is
int -4 bool, this assertion succeeds with t, = int and i2=
bool.
There are four forms of simple assertion which are
convenient abbreviations:
(4a) E:: t e combines (la) and (2a)
(4h) E:> t combines (1 b) and
(2)
(5) E::jOrmat combines (la) and
(3); it is short for E::1, -^:.-:format.
(6) e, =e2 asserts
that e, is
equal to e2; this
is a special case of (3).
Finally, there are two forms of simple assertion which
correspond to introducing auxiliary functions into the
evaluator:
(7) el-4 e2 asserts
that el simplifies to
e2, using
the simplification rules which tell how to evaluate primitives. See
Section 5.2.2.
(8)
el e2
asserts that el unrolls to e2, using the rule for
unrol‑
ling fix. See Section 5.2.5.
By
convention we write a lowercase e for
the value of the expression E, and
likewise for any other capital letter that stands for an expression. If a lowercase
letter x appears in an assertion, X
appears on the left hand side in
the conclusion, and no premise has the form x
or then
the
premise X -.17 is implied.
A reminder of our typographic conventions: We use
capital letters for meta-variables denoting expressions, and
lowercase letters for meta-variables denoting values; both may be
subscripted. Thus expressions
appear on the left of ::, :>, and in assertions,
and values everywhere
else.
The value constructors that are not symbols are closure
and fix.
An
italicized meta-variable indicates where that variable will be bound by
a deterministic evaluator, as explained in the next section.
5.1.2. Determinism.
In order to find the principal type of an expression E, we try to prove E:> 1, where t is a new meta-variable. If
a proof is
possible, it yields a value for I as well. Similarly, we can
use the inference rules to find the value of E by trying to prove e.
We would like to be
sure that an expression has only one value (i.e., that E-e, and implies
e,= e2). This
is guaranteed by the fact that the inference rules for evaluation
are deterministic: at
most one rule can be applied to evaluate any expression. because
there is only one conclusion for each syntactic form. When there
are multiple rules abbreviated with or, the first premise of
each rule excludes all the others. In a few places we write
all, al,, a21, a2„2 or ... or ak,, else a2,
..., an
as
an abbreviation for
all, ..., al„, or an, •.., a2„, or .. or a 4,, ... ak„,
or
not a , , , not a2,,...,
not ak 1,
a,, a,,.
The fact that the rules are deterministic is important for
another reason: they define a reasonably efficient deterministic program for
evaluating expressions.
Not only has an expression just one value, but
it also has just one principal type (defined by the :> relation). It is
not true, however, that an expression has only one type. In particular, the
auxiliary rule :: may allow types to be inferred for an
expression in addition to the principal type. We say more about
what this means for deterministic evaluation in Section 5.2.6.
In each rule one occurrence of each meta-variable
is italicized. This is the one which the deterministic evaluator will use to
bind the meta-variable. For example, in x 11, 1, and
12 are bound to the types of E, and E2, respectively; they are used in x 10 to compute I, x 12,
the type of [E,, E2].
The italic
occurrence of e may
be omitted if it is e, as explained earlier.
Thus the e, and e2 in x 10
are bound by omitted premises E, c, and
E2
e 2 . The
italics are not part of the inference rules, but are just a comment
which is relevant for deterministic evaluation, and may be a help to the
reader as well.
It may also be helpful to know Cheat the premises
are written in the order that a deterministic evaluator would use.
In particular, each meta-variable is bound before it is used. In this
ordering, the expression in the conclusion should be read first, then the
premises, and then the rest of the conclusion.
5.1.3.
Feedback. An
important device for keeping the inference rules compact is that a
value with a known type can be converted into an expression, which
can then be embedded in a more complex expression whose
type and value can be inferred using the entire set of rules. This feedback from the value space to the
expression space is enabled by the syntax e 1.
This is an expression which
has value e and
type t. This
form of
expression is not
part of the language, but is purely internal to the inference rules.
Usually the type is not interesting, although it must be there for the feedback
to be possible, so we write such an expression with the type in a small
font, a*„ to
make it easier for the reader to concentrate on the values.
If t is
omitted, it is assumed to be type. In addition, we often drop the
# t entirely
in the text of the paper, where no confusion is possible.
5.1.4. Initial environment. The expression which
constitutes the entire program is evaluated in the initial environment po given in Table VII.
This provides meaning for standard constants such as true and
type, and for standard operators such as x and typeOf.
5.2. The Rules
The inference rules in Table VI are organized
like the syntax in Table Ill, according to the expression
forms for introducing and eliminating values of a particular type.
A particular rule is named by the constructor for the type,
followed by 1 for introduction or E for elimination; thus is the rule
for A-expressions, which introduce function values with types of the
form to
t. Each line is numbered at the left, so that, for example,
the conclusion of the rule for A-expressions can be named by
-410. If there is more than one rule in a part of the table labelled by
the same name, the less important ones are distinguished by letters a, b,...; thus x Ec is the rule for AS.
Auxiliary rules, with conclusions which are not part of the syntax, appear
overleaf. Most of these
define the --4 function for simplifying values.
5.2.1. Booleans, pairs, and names. The inference rules for
booleans are extremely simple,
boolE (1)
E bool, El t, E2 t,
(2) { Eo true, El a or Eo false,
E2 e else ifl(e0, el, e2)}
(0) If Ec, THEN E, ELSE E2:
> t e
The boolE rule says that the expression I
F E0 THEN
E1 ELSE
E2
-type-checks
and has type t if E0 has type bool, and E, and E2 both have type
t for some t. The
value of the IF is the value of E, if
the value of E0
is true, the value of E2
if the value of E, is false. if the value of E, is not known,
the IF evaluates to a symbolic value (unless of course it fails to terminate).
Thus
(A) IF true THEN 3 ELSE 5
has type int and
value 3. The types and values for the constants true, 3, and 5 come from pa.
TABLE VII
Initial Environment Po
![]()
![]() Name Type Value
Name Type Value
true false
0, I, ...
+, o,
void nil
x, typeOf
fstt sndt
x • -
- • 0
shrinki coerceF xl
xl
xtd
boot
bool int
int x int
-4 int
type
void
type x
type type
type -o type
d: type xx typeOf d-oo d
: type xx -o
type)
1: type x x (type -.1st( /I-. type type -+ type
type
type
type type x
type
type : type x x (t type)
type -.t: type x x (type fstt r)
type x type type
type x type type
d type xx d-o type
r :
type -oo typeOf(d: type xx h : d) d: type -oo : type
-oo d)
true false
void
nil x, typeOf
C)., 0
0
At : type IN
fst x -It At : type IN snd x x
- 0
shrink F
coerceF
xt (d must he declaration) xt
Ad: type IN At: type IN LET (d', b): -xt 't IN shrinkF(d, d) /o
![]() Note. The following primitives are not in the
initial environment, but are generated by the inference rules:
Note. The following primitives are not in the
initial environment, but are generated by the inference rules:
iffle„, el, e2)--, c, if =
true, e2 if eo = false
iftruelle,,, 1) • e, if = true, undefined if eo = false
fst,snd,rhs
with meanings given by the w. rules in 5.
p„ maps each name to type value. It also
maps the symbol depth to 0.
We can display this argument more formally as an
upside-down proof, in which each step is explicitly justified by some
combination of already justified steps, denoted by numbers, and
inference rules, denoted by their names (together with some meta-rules which
are not mentioned explicitly, such as substitution of
equals for equals).
(A l) IF true TIIEN 3 ELSE 5 :: int 3 2,3,4,boolE
(A2)
true :: bool true NI
(A3)
3 :: int 3 NI
(A4) 5 :: int. NI
In this display we show the conclusion at the
top, and successively less
difficult propositions below it. Viewing the inference
rules as a (deterministic) evaluation mechanism, each line shows the
evaluation of an expression
from the values of its subexpressions, which are calculated on later lines.
Control flows down the table as the interpreter is called recursively
to evaluate sub-expressions, and then back up as the recursive calls return
results that are used to compute the values of larger expressions.
The rules for pairs are equally simple.
![]() (I) E,::th E2 12
(I) E,::th E2 12
![]() (0)
[E,, E2]:>11 x
/2 [el,
e2]
(0)
[E,, E2]:>11 x
/2 [el,
e2]
![Text Box: x E (a0) fst::(t x t,)—, t (b0) snd::(i, x t.
x I says that the type of [E,, E2] is t, x t2 if t, is the type of E,, and its value is [e,, e,]. x E gives the (highly polymorphic) types of the primitives fst and snd that decompose pairs.
(I) p(N).---.:1—e](39-PebbleOCR_files/image060.gif)
![]()
![]()
![]() (0)
N:>t=e
(0)
N:>t=e
We can use NI to show
[i = int 3]1--- IF true THEN i
ELSE 0 :: int 3
following the proof of (A) above, but replacing (A3) with
(A3') [i int — 3 ]1— :: int =- 3. NI
5.2.2. Functions. The
pivotal inference rules are —*I (for defining a function
by a 1-expression) and --,E (for applying a function). The —*I rule is
concerned almost entirely with type-checking. if the type-checks succeed,
it
returns a closure which contains the current environment p, the declaration
d for the parameters, and the unevaluated expression E which is
the body of the 1-expression. A later application of this closure to an argument
E„ is evaluated (using —FE) by evaluating the expression
LET
d— Eo IN E (1)
in
the environment p which was saved in the closure.
We begin with the basic rule for A, omitting line
2, which deals with dependent function types:
(1) T, ,
t', t, typeOf
d to, to t =11
(3) p(depth)=n,
p [depth = n + I] =p'
(4)
p' LET newc(n + I)IN
E t
![]() (0)
(AT, IN E) :> t1 = =closure(p', d, E).
(0)
(AT, IN E) :> t1 = =closure(p', d, E).
d
is the parameter declaration, to is the parameter type, e„ is the
argument value, t is
the result type, and t, is the type of A-exp.
The expression T, in the A roughly gives
the type of the entire A-expression. Thus
(B) Ai: int -4 int IN i+ 1
has T, = (i: int int), and its type (called t,)
is int int.
The value of T, is
called 1',; it differs from 1, in that the
declaration 1: int
has been reduced to
its type int. This is done by ), which accepts a T,
which evaluates to
something
of the form d—* i, and computes first to as typeOf d (using
e to evaluate typeOf), and then I, as 10—.1.
The --->e rule for typeOf just decomposes the declaration
to the primitive form N: t, and then strips off the
N to return t. The cases for dependent and inferred products
(lines 2 and 5) are discussed later.
The idea of (—,I4) is that if we can show that
(1) type-checks without any knowledge of the argument values, depending
only on their types, then whenever the closure is applied to an expression
with type t, the resulting (1) will surely type-check.
This is the essence of static type-checking: the definition of a
function can be checked independently of any application, and
then only the argument type need be checked on each application. (—d4)
is true if we can show that
LET
newc(n + I IN E (2)
has the result type I, where
newc(n + I) is a constant, about which we know nothing except that
its type is d. In other words, newc(n 1) is a binding
for the names in d, in which each name has the type assigned to it by
S. Here n is the depth of nesting of A-expressions. It is
straightforward to show that newc(n + 1) does not appear in p, and
therefore does not appear in t either. This ensures that the proof that (2)
has type t does not depend on the values of the arguments.
For our example (B), we have
LET
newc(l),,,,,„ IN i + 1 (3)
Using this, (3) has type int
if p[i = int — rhs!newc( I )] + 1
has
type int. Since i + 1 is sugar for plus[i, 1], its type is given by the result type
of plus (according to —,E1), provided that [i, 1] has the argument type
of plus. Since
plus :: int x int int
we have the desired result if [I, 1] :: int x int.
Using x I this is true if i :: int and I :: hit. According to
NE, the former is true if p(i)gr,int— e0. But in fact
p(i) = int rhs!newc(1), so this is established. Similarly, the initial environment tells us
that p( 1) = int— 1.
We can write this argument more formally as follows:
(BI) pi—
LET newc(1),,: int IN + 1
:: int 2,
:E
(B2)
p, 1
:: int, 3, E
where p ,= p[i = int — rhs!newc( 1 ) ]
(B3) p , 1— plus :: t -4 int, [i, I] ::t 4,5
(134) p plus :: int x int int 7, NE
(B5)
p [1,1] :: int x int 5,
x E
(B6)
int, I :: int 7,
NE
(B7) p,(i).--zint—e,,p,(1)r-zint-1,
p,(plus),,-
int x primitive(plus) inspection.
We now consider the non-dependent case of
application, and return to A-expressions with dependent types in the next
section,
(I) F coerce(E0, to) :: to e0
(3) { fie° e else
f !eo = e)
(0) F
E0:>t
The type-checking is done by —nEl, which simply checks that the argument
E, can be coerced to the parameter type to of the function. The coercion
is done by typeE; line (1) of this rule says that if E has type 1, then
it can be coerced to type t simply by evaluating
it. Line (2) says that if E has
type t', and there is a coercion function coerceF(e,i), then E can
be coerced to t by applying the function. The coercion
function is computed by —411, which has two parts. Lines (1-5)
compute coercions for constructed types from those for
simpler types: a product can be coerced by coercing its first and
second parts, a function by composing it with a coercion from
the desired argument type and a coercion to the desired result type, and
a declaration by coercing the value part. Lines (6-8) give coercion
rules
for particular types, which are discussed in connection with these types:
inferred products, bindings, and extended types. Coercions are not a
fundamental part of the language, but they are a great convenience to the programmer
in handling the inheritance relations among abstract types.
–+E3 tries
to use the –4 rules for evaluating applications to obtain the value
of f when
applied to the argument value e„. If
no –4 rule is applicable, the value is just /leo, i.e.,
a more complex symbolic value. The
rules have two main cases, depending on whether f is a primitive or a closure.
For J. an arbitrary primitive fo we use the main –4 rule,
for
each <arg, result> pair in each primitive fo
(0) e
Because of the type-check, this will succeed for a
properly constructed primitive unless e„ is a symbolic value, i.e.,
contains a newc constant or a fix.
Thus the M4 rules can he thought of as an
evaluation mechanism for primitives which is programmed entirely outside
the language, as is appropriate for functions which are primitive in
the language. In its simplest form, as suggested by the –4 rule above,
there is one rule for each primitive and each argument value, which gives the
result of applying that primitive to that value. More compact and powerful
rules are also possible, however, as–, a – e illustrate.
Note that the soundness of the type system
depends on consistency between the types of a primitive (as expressed in
rules like x Ea – h), and the–, rules for that primitive ( –4 a – h for fst and snd). For each
primitive, a proof is required that the –4 rules give a result for
every argument of the proper type, and that the result is of the proper
type.
If f is
closure(p„, d, E), --4 first
computes typeOf d, which
is the type that the argument e„ must have. Then it evaluates the closure body E in the closure
environment p„ augmented
by the binding d– e„. Note
the parallel with –04, which is identical except that the
unknown argument binding newc" replaces the actual
argument binding d–e„. The success of the type-check made by –04 when
f was
constructed ensures that the LET in –4 will type-check.
The remaining –, rules evaluate the primitives typeOf
(discussed above), (Section 5.2.4), fixtype (Section 5.2.5), coerceF
(discussed above), shrink F (Section 5.2.4), and xtd (Section 5.2.4).
If f is
neither a primitive nor a closure, it must be a symbolic value. In this
case there is not enough information to evaluate
the application, and –,E3 leaves it in the form flea. There is no hope
for simplifying this in any larger context.
5.2.3. Dependent
.functions. We now return to the function rule, and consider
the case in which the A-expression has a dependent type,
(2) T, r,,t1Nnewc(n
+ I )--4 t,
(3) p(depth)=
n, p[depth
= n + I]= p' (4)
p' I-- LET
newc(n+ )*d IN E t (0) (2 T, IN E):> t, -closure(p', d, E)
The only difference is that —412 applies instead
of —di; it deals with a function whose result type depends on the
argument value, such as the swap function defined
earlier by
(C) snap: — 2(t,: type x 12:
type) (r, x r2—,12 x r,) IN
A(x1:11 x x2:
/2)--,
12 x r, IN [x2' xi]
The type expression for the type of swap (following the first A) is sugar for
(t,: type x 12: type) C> (A B': (r,: type x 12:
type) type
IN LET B' IN
(I, x t2-4 r2x t,))
The operator l> is very much like but where --• has the simple
type
type x
type—*type
1> has the more complex type d: type xx : (d--+type)—ntype Thus the type of swap is
(ti: type x 12: type) C> (4)
closure(p, B': (t,: type x /2: type), LET B' IN t x /2 -4 12 x i,).
In this case the parameter type of swap is just (ti:
type x12: type); we do not use typeOf to replace it
with type x type. This would be pointless, since the names t, and t, would remain buried in the
closure, and to define equality of closures by the a-conversion rule of
the A-calculus would take us afield to no good purpose. Furthermore, if
elsewhere in the program there is another type expression which is
supposed to denote the type of snap,
it must also have as its main operator, and a declaration
with names corresponding to 1, and 12.
This is in contrast with the situation for a non-dependent
functon type, which can be written without any names. The
effect of leaving the names in, and not providing a-conversion between closures,
is that two dependent function types must use the same names for the
parameters if they are to be equal. (Note, in a more recent version of Pebble,
incorporating many changes, we provide an equality for closures which
is true when they are a-convertible.)
![]() We
do, however, need to compute an intended result type against which to
compare the type of (1 ). This is done by applying the closure in (4) to newc(
); note that this new constant is the same here and in the instantiation
of -.14. In this example, this application yields
We
do, however, need to compute an intended result type against which to
compare the type of (1 ). This is done by applying the closure in (4) to newc(
); note that this new constant is the same here and in the instantiation
of -.14. In this example, this application yields
rhs!fst!newc( I) x rhs!snd!newc( I )-4rhs!snd Inewc( I )
x rhs!fst!newc( I ))
which
we call t.
The body is typechecked as before using -.14. It goes like
this
(CI ) p LET newc( I ) fOype /2:type IN
A.
x1: 1, x
x2: t2 r2
x I, IN [x2, x2]
:: 2,
:E
rhs!fst!newc( I )x rhs!snd!newc( I )-.rhs!snd!newc( I )x
rhsffstInewc(1 ))
(C2)p, A(xt: 1,
x x2: 12)
-+ t2 x t, IN [x2, x1 ]
:: equality,
3, -*I
rhs!fst!newc( I )x rhs!snd!newc( I)-. rhsrhs!snd!newc( I
)x rhs!fst!newc( I )), where p, = p[i = type rhsffstInewc( I ), 12=
type- rhs!snd!newc( I )],
(C3)p,
1— LET newe(2),,,, rhs!islInewc( I ) x rlIsIsmIlnewc(
I ) IN[x2, x,]
:: 4, :E
rhs!snd!newc( I) x rhs!fst!newc( I ))
(C4)p
21—
[x2, x ] rhs!snd!newc( I) x rhsffstInewc( I )), 5, x E
where p2 = p, [x,
= rhsffst !newc( I )- rhsffstInewc(2 ), x2:rhs!snd!newc(
I )- rhs!snd!newc(2))],
|
(C5)p21--- x2 ::
rhs!snd!newc( I ), (C6)
p2(x2),--.zrhs!sndlnewc(
)-eoz, |
p, x, rhs!fst!newc(l) 6,
NE p2(x,) z rhsffstInewc(1)- en, inspection. |
Observe that we carry symbolic forms (e.g.,
rhs!sndlnewc(1)) of the values of the arguments for functions whose
bodies are being type-checked. In simple examples such as
(A) and (13), these values are never needed, but in a polymorphic
function like swap they appear as the types of inner functions.
Validity of the proof rests on the fact that two identical symbolic values
always denote the same value. This in turn is maintained by the applicative
nature of our system; the fact that we generate a different newc(n)
constant for each nested A-expression where n is the depth of nesting
maintained by the depth component of p, and the fact that if p(depth)=
11, newc(n') with n' > n never
appears in p.
A function with a dependent type d t f is
applied very much like an ordinary function,
-.E (2) F d f,, fi# d E0) t, rhs(d E0)
en
(3) { f! e„ e
else f
le = e}
The only difference is that —E2 is used for the
type computation instead of -+El. This line computes the result type of
the application by applying f, to
the argument binding d r En; in
evaluating this binding En is
coerced to the argument type typeOf d, which we call t„. It is exactly parallel to -412,
which computes the (symbolic) result type of applying the function to the
unknown argument binding newc,,,d. We apply fl to (I-- En rather than to
En because
typela, which constructs di> f, expects
a binding as the argument of f,. The reason for this is that in —'E2 we
do not have an expected type for E0, but we do have
a declaration d to
which it can be bound. It is the evaluation of the binding En that coerces the argument; there
is no need for the explicit coercion of -4E1.
5.2.4. Bindings and declarations. The main rule for binding
shows how to use a binding in a LET to modify the environment in which a sub-expression
is evaluated (:E). A binding is constructed by the primitive function
—, defined by -4f. The
tricky case of recursive bindings (:la and NI2) is discussed
in Section 5.2.5.
The type of — is given in Table VII; it is the value of
d: type xx typeOf d --» d.
Thus it takes a declaration d, and a value whose type is
typeOf d, and
produces a binding of type d. It is defined by which has
four cases, depending on the form of the declaration value.
In evaluating D— E, if the declaration is void, typeOf D is void so that E must have type void also,
and the result is nil. If D is
N: t, it
must be possible to coerce E to type typeOf D,
which is t. If
this yields e, the
result is the binding value N e; see Section 5.2.2 for a discussion of coercion.
These are the base cases. If the declaration is di x d2, E must have type typeOf
d, x typeOf d2, and the result is the value of [di fst E, d2 —snd E].
Thus
i: int x x: real — [3, 3.14]
evaluates just like
[I: int
— fst[3, 3.14], x: real — snd[3, 3.14]]
namely to 3, x— 3.14]. All three of these cases
yield d as the type of
`-the
binding.
The rule for a dependent declaration is more
complicated. It is based on the idea that in the context
of a binding, do= di 012
can be converted to d, x
d2 by applying f2 to
fst E to
obtain d2. The binding then has the type and
value of d, x
d2 E. Thus
1: type xx x: — [int, 3]
has
type I: type x x: int and evaluates to [t —
int, x 3]. In this case the type of the binding is not do. but the
simpler cross type d=dix d2.
This idea is implemented by and —'13. The former
computes typeOf d, Of, as t,
0[2, where t,
is typeOf dl, just as for an ordinary product,
and 12 is
the composition J2 o typeOf.
In the rule, the composition is written out as a 1-expression. The
skint& clause checks that D is
really a declaration. To evaluate a binding to d, 0./2,
---43 applies J2 to
fst E to
compute d2, and then proceeds as for d, x d2.
For an inferred product d, ®J 2, e5 computes typeOf D as 1,012, where
t, is
typeOf d, as before, and f2 isf2.
rhs, since f2 infers
a binding (of type fstt (11) and f2
should infer the rhs of that binding (of type fstt typeOf d,
). To evaluate a binding to d, 0f2, just evaluate a binding to d,; the argument
has already been coerced to have the proper form.
The rule for LET B IN E has
exactly the same cases,
:E (I) B::void, E:>
te
(2)
or
B:: (N: to),
rhs B c0, P[N = to — co] E :> t
(3)
or
B x d2, snd
B b2, LET fst B IN LET b2,d, IN E :> t
(4) or B:: d, Of f#di d2, LET b #d1 x IN
E :> te
(0)LETBINE:> te
If B has
type void, the result is E in
the current environment. If B has
type N: 1,,, the
result is E in an
environment modified so that N has
type to and
value obtained by evaluating rhs B.
Thus
LET i:
int — 3 IN
i + 4
has the same type
and value that i+4 has in an environment where 1: int — 3, namely type int
and value 7.
If B has
a cross type, the result is the same as that of a nested LET which
first adds fst B to
the environment and then adds snd B.
The rule evaluates snd B separately; if it said
LET fst B IN
LET snd B IN
E
the
value of snd B would
be affected by the bindings in fst B.
Finally, if B
has a dependent type, that type is reduced to an ordinary
cross type d, x
d2, and
the result is the same as LET B' IN
E, where
B' =1) "
„ d, has the same value as B, but an ordinary cross type.
The last case will never arise in a LET with an explicit binding
expression for B, since
:I will always compute a cross type for such a B. However, when type-checking
a function such as
At: type
x x x: t int IN E
—.14 requires
a proof of LET newc, of IN E:: int
where d, 0 f is
the value of t: type xx x: :E4 reduces this to LET newc #t: type
x x rsl!newc IN E :: int
![]() (al)
11 [ ] LET b" IN E:: t e
(al)
11 [ ] LET b" IN E:: t e
(a0)
IMPORT B IN
E :> t•• e
The IMPORT construct has a very simple rule, :Ea.
This says that to evaluate IMPORT B
IN E, evaluate
E in
an environment which contains only the binding of B.
There is a special coercion rule ---41:7 for bindings,
which says that a binding B can be shrunk to a
binding of type d. Shrinking
is defined by which calculates a function f that shrinks d' to d. It succeeds if for every simple
declaration N: I of
which d is
composed, B$N has
type t. The shrinking works by using N: t — B$N as the value
corresponding to N: t, and
putting these simple bindings together according to the structure of d. The motivation for shrinking
is to allow extra elements to be dropped from a binding; see Section
2.3 for examples.
5.2.5. Recursion. Recursion is handled by a fixed point
constructor. If F is
an n-tuple of functions 171
with types d
(11, and d
x • • • x d„ =
d, then FIX F
has type d and is the fixed point of F; i.e., F(FIX F)= (FIX F). The novelty
is in the treatment of mutual recursion: d may declare any number of
names, and correspondingly FIX F binds
all these names. The following sugar is convenient for
constructing F:
REC D, E1,...,D„— E„ for
FIX((a. B':D, x • X D„
IN LET B' IN
D, —E,
A B': Dix •••x D„ IN LET B' IN D,, E„)).
For example,
REC
g:
(int —o int )— A x: int —o int IN IF x=
0 THEN I ELSE x * h(x12).
h: (int
int)— A y: int —* int IN IF y < 2
THEN 0 ELSE g(y — 2)
, has type
g: (int
-4 int) x In (int —0 int).
Its value is a binding for g and It in which their values are
the closures we would expect, with an environment p .0 that contains
suitable recursive bindings for g and
h. We
shall soon see how this value is obtained, but for the
moment let us just look at it:
[g closure(pR,,,
x: int, IF x = 0 THEN I ELSE x *
h(x12)). h closure(p
y: int,
IF y < 2
THEN 0 ELSE g(y — 2))]
where
p gh= p[g:
(int -4 int) rhslfst!fix(f, f ), It: (int int) – rhs!snd!fix(f,
where
f= [closure(p,
B': d, LET
B' IN
g: (int
--4int)– x: int –+ int IN IF x= 0 THEN 1 ELSE x*h(x/2),
closure(p, B': d, LET B'
IN (int –4 int)
–). y: int
–*int IN
IF y <2 THEN 0 ELSE g(y-2)],
where
5= g:
(int –n
int) x (int --4 int)
The fix values inside po, are what capture the
infinite value of this recursive binding in our
operational semantics. Of course, if g is looked up in pg,, (as it will be, for example,
when we compute h(3)), we do not want to obtain rhs!fst!fix(f,f) as
its value; rather, we want closure(pgh, x: int, ...). To
get this we unroll the fix
value; that is, we replace fix(f',/) by f'(fix(f',f)), which
evaluates to a closure. This unrolling is done by the
rule, which also deals with the possibility that there may be an
operator such as rhs outside,
(I) e e, e2,
{w!e2 e'
or w!e2--,* e' }
(2)
or e olfix(f [w!
f' ",
fix(1", f )= e'
(3) or f' closure(x), f'!fix(
f 1) e", w!e" e' }
(0) e –» e'
This rule unrolls rhs!fst!fix(ff ) by first computing
fst!fix(f,f) fix(f
where f' is
the value of fst! f (the functional
for g), using 2, and then
fixtf g
closure(pg„, x: int, ...)
using
–4) 3 and –4E, and finally simplifying rhs!fix(f',f) to closure(pgh,
x: int, ...) using 1 and --4c. Thus, each time g or h is looked up in pgh, the
NI and –4> rules unroll the fix once, which is just enough to keep the
computation going.
For the persistent reader, we now present in
detail the evaluation of a simple recursive binding with one identifier,
and an application of the resulting function. Since some of the
expressions and values are rather long, we introduce names for them
as we go. First the recursive binding:
(D) R EC P: (int –*int) -- n: int int IN
IF n <2 THEN n ELSE P(n – 2)
We can write this more compactly as REC
DP L
where
DP= P: (int
-*int),
L = A n: int
int IN EXP,
EXP = (IF,: <
2 THEN n ELSE
P(n -2)).
The table below is a proof that the value of (D) is
P: (int int) - closure(po, n: int, EXP)
It
has been abbreviated by omitting the # types on values which are used as
expressions. The evaluation goes like this. First we construct the A-expression
for the functional whose fixed point f we need (D3) and evaluate it to obtain a
closure (D4). Then, according to :1a2, we embed fin fix(f,f, ) and unroll it.
This requires applying f to
the fix (135), which gives rise to a double LET (D6), one from the
application and the other from the definition of the functional.
After both LETs have their effect on the environment, we have po, which contains the necessary
fix value for P ((D7)-(D10)).
Now evaluating the A to
obtain a closure value for P that contains
p is
easy (D12)-(D13),
(D1) pi--RECDP-L::dpbp (Dia)
(D2)
P: int
int = dp
(D3) pi— (AB': DP -0. DP IN
LET B' IN
dp f
(D4) closure(p,
B': dp, LET
B' IN
dp L) = f
(D5)
f (fix(f,
f)) hp
(D6) p B': dp fix( f, f) bf,
pi—LET hf IN
LET B' IN
dp-Lbp
(D7) B': dp - fix( f, f)= bf
(D8)
pji— LET B'
IN dp bp,
where pr= p[B': dp - fix( f, f
(D9)
rhs B' rhsffix(f, f )
(D10) p dp bp,
where pfp=- pj[P: (int int)- rhsffix( f, f)],
(D11) pot-- L closure(pfp, n: int, EXP)
(D12) P closure(po, n: int, EXP)= by
:1, la, 3,5
typelc, 2
definition
-4 1, 4
definition
E, 6
#,f; 7,:E, 8
definition :E, 9, 10
E,
NI 11,
12
I
definition.
Note that this evaluation
does not depend on having A-expressions for
the values.Of the recursively bound names. It
will work line for ordinary expressions, such as
REC i: int —j+ I,j: int 0
which
binds i:— I and j: 0. However, it may
not terminate. For instance, consider
REC (i: int xj: int) [j+ I,
i].
In
fact,
REC
(i:
int xj: int) — [j + 1, 0]
will also fail to terminate, because the rules insist on
evaluating [j-1- I, 0] in order to obtain the 0 which is the value of j. REC
also fails if type-checking requires the values of any of the
recursively defined names, as in
REC t: type— int, g: int
int — A I: int int IN LET x: I— i + I
IN x * x
because
in type-checking the f function we only have a newc value for 1, not
its actual value int.
Now we look at an applicationof P:
(E) LET (REC P: (int int)— A n: int int IN
IF fr < 2 THEN n ELSE P(ti — 2))
IN P(3)
This
has type int and value I, as we see in the proof which follows. First we get
organized to do the application with the proper recursive value for P (El
)-(E2). The application becomes a LET after P and 3 are evaluated (E3)-(E5).
This results in an environment p „3 in which n 3, so
we need to evaluate PO — 2) (E6)-(E7). Looking up P we
find a value which can be unrolled (E8)-(F9) to obtain the recursive value
closure(pf,„ n: int, EXP) again (E10)-(E11). Since n — 2
1 (E12), we get the answer without any more recursion (E13)-(E15).
![]() (El)
) p LET
REC DP L IN P(3):: int 1
(El)
) p LET
REC DP L IN P(3):: int 1
(E2) p P(3):: int 1,
where p,,= p[P = (int —) int) — closure(pfp,
n:
int, EXP)],
(E3)
 p P (int int) closure(po,
n: int,
EXP)
p P (int int) closure(po,
n: int,
EXP)
(E4)
n: int
3 n — 3
(E5)
p LET
ti — 3 IN EXP ::inter 1
(E6) p „ IF
n < 2 THEN n ELSE P(ti — 2) :: int 1
|
PEBBLE, A KERNEL LANGUAGE where p„3 = pfr[n = int — 3] |
341 |
|
(E7) p „, Mit
— 2):: int I |
E, 8,
12, 13 |
|
(E8)
(int -4 int) closure(pf,„
n: int, EXP) |
NI, 9 |
|
(E9) rhs!fix(f; f) -4> closure(pro n: int, EXP) |
"n4 I |
|
(Ell) rhs!bp closure(pm, n: int, EXP) |
"`"4
b |
(E12) p„31-- n — 2 :: inter1 NI,
-4E,
(E13) p I-- LET n— I
IN EXP::int— I :E,
14
(E14)
p,„ IF n < 2 THEN
it ELSE
P(n — 2)
:: int I, 6001E, 15
where p, = p fp[n = int — 1],
(E15) p „, — n :: int 1. NI.
It should be clear to anyone who has followed us
this far that we have given a standard operational treatment of
recursion. There is some technical interest in the way the fix is
unrolled, and in the handling of mutual recursion.
5.2.6. Inliraing types. The inference rules give a
way of computing a type
for any expression. In some cases, however, an expression may have additional
types. In particular, this happens with types of the form d 0 f and typeOf!(d 0 f), because pairs with these
dependent types also have ordinary cross types, which are the ones computed by
the inference rules. To express this fact, there is an additional
inference rule :: which tells how to infer types that are not
computed by the rest of the rules,
(I)
E:> t
(2)
or{txt, 0 f, E::tixt2ort::::41x/2,E::11
Of}, f#11-iype(fst
E) t2
(3) or
E t ()for t t' Of, E
t'
(4) or E 1',
(ezt.xiqd, (N-
t, h)) or
t xt!(d, N t', b)))
(0)
E
::1 says that the principal type of E is one of its types. ::2 turns d 0 f into d x t by applying f to fst E to compute t; then
it checks that E has
type d x
t. This
is a reflection of the fact already discussed, that a pair may have many
dependent types, as well as its "basic" cross type. This inference
can
go
in either direction. ::3 says that if E has type t then it has type 1.
This follows from which gives the only way of introducing
a value with O type. This inference can also go in
either direction. ::4 says that if E has
an extended type xt(d, h), it
also has the base type rhs fst b, and
vice versa. This rule reflects the idea that extended types are
a packaging mechanism for asociating a set of named functions and
other values with a
type so that the whole package can be handled as a unit,
but they do not introduce any new kinds of values, or provide any protection.
The rule is sound because it is the only rule that applies to
expressions with extended types.
5.3. Execution
The inference rules in Table VI tell us how to
simultaneously type-check and evaluate a Pebble expression. With a few
changes. however, we can turn them into rules which type-check an expression
and produce code which
can be executed to yield a value; these can reasonably be regarded as rules
for a compiler. The code takes the form of a symbolic value consisting of
the primitives of Table VII and newc(n), combined recursively using one of the forms
e2), e2, N: e, N c, e, n),
where N is
a name and n is
a natural number. The cl form is the result of evaluating a
A-expression; its intuitive meaning is that if values are supplied for
newc(1), newc(n), then e can
be evaluated to yield a value without any newt's.
Two changes are required.
The last two lines of the A rule,
-41, become
(4) p' LET newc(n + I ),+4 IN
E t e
(0) (A T, IN E):
> t ],
e, n + 1)
The --.4d rule for applying
a closure is replaced by a rule for applying a cl:
(dl )s+(n—e0)1---el--+
e" (do) cl(s. e,
n)! e„—+
This rule makes use of a new function for executing a
code expression e in
the run-time environment s. We write s e e', meaning execute e in run-lime
environment .s to yield e'. The
rule above says that to apply a cl to e„, add e,
to the existing run-time environment and then execute e.
An s has the form it, —el +
•-•+nk— ek; it
supplies values for the arguments of procedures at levels ni,...,nk which
were referred to
symbolically as newc(n,), newc(nk) in e. Two such objects which
define disjoint sets of n, can be combined in the obvious way to yield an s which defines
the union of the sets.
The execution function is defined by the 1---4 rule in Table VIII. Most of the
lines just apply the rule recursively. Line (2) uses the rules to evaluate
an application of a primitive or a cl. Line (7) evaluates newc(n) by looking
up n in the environment s; if
s is
not rich enough, it leaves the newc(n) alone.
TABLE VIII
Run-Time
Execution
![]()
![]() or ezlel(b, e „ n), s tti—*
b' 5+ (n n—ne'
or ezlel(b, e „ n), s tti—*
b' 5+ (n n—ne'
orerzN:r,st--tn—+r',N..r=e'
or eqS(s+s',s, n)—e'
otter
newc(n), s(ii )= e' else c = e'
eke e= e'
![]() s e'
s e'
= ?I e,
look up{s, me)
or
s' =.r + si, indudes(s, includes(s,
s'2)
![]() include*, s')
include*, s')
= IT •••-• c
or s =s, + s2, {lookums,, n, c) or Inokup(s2, n,
![]() toukup(s,n, e)
toukup(s,n, e)
include*, s').
includes(s', s)
![]()
![]() eqS(s, s')
eqS(s, s')
Line (6) evaluates a ci in two steps. First, it
augments the cl's saved environment by adding in the current
environment. Then it non-deterministically splits the
resulting s into
two parts s, and
sr, and executes e, in 5, this will supply values for some of the newt's in e, , and do any applications
which knowing these values allows. The result is a new piece of code el, which still needs the
values in 52, as well as a value for its argument
newc(n), to he completely evaluated. We therefore bundle it back
up into cl(s,, e',, n). If s, is (11 e), this corresponds to one step of /3 reduction
in which e is
substituted for newc(n). The non-determinism reflects the freedom
of the implementation to do the substitution and partial evaluations
in any order. We should prove, as a theorem, that the result of applying
the closure does not depend on how these choices are made.
Note that during this execution types play no
role; the type-checking is all done during the process of constructing the
code. The converse is not true, however: during type-checking, when a
type-returning function is applied, it may be necessary to execute the
application in order to obtain a sufficiently reduced value.
For example, consider
LET id(r: type n 1)):— (A x: r IN x) IN id(int)(3)+ I
The type Of id is
t: type
Del([ ], !(rhs!newc(n),
rhs!newc(n)), n)
and the result type of id(int) will be el( • • • )!(t — int). in order to type-check the
"+", this must be reduced to int by the—, rules.
In general, however, it is not necessary or appropriate to
apply a cl whenever the function part becomes known. Doing this is
doing inline expansion of applications whenever possible, and
leads to bulky, perhaps even infinite code. It is therefore appropriate
to modify the uses of 2 by using some heuristics to decide whether a cl
should be applied. If e is a top‑
level symbolic value e i!e2,
and e, cl( •-• ), it should definitely be applied;
this rule ensures that any cl application not nested inside another cl
will be done. Otherwise the cl probably should not be applied, unless the body
is fairly short, or this is the only application.
A related issue is the treatment of LET B IN
E. The evaluation rules in Table VI always substitute
for the names in the B wherever these names appear
in E. This also is likely to increase the size of the result. An alternative is to treat
LET more like A, by changing :E2 to
or B (N:1„), {rhs B e„,
p[N1 = to — :: e
or (AN: to
1 N
E) to t cl([],e,a),let(b,e,n)=e}
Later 1--,3 will evaluate the let, using the same
heuristics as those for cl. The or in this rule allows
a non-deterministic choice about expanding the LET, unless the
second choice fails to type-check because the type-correctness
of E depends on the value bound to N by B; this is likely
to be true if to is
type, and may be true in other cases as well.
5.4. Deterministic Evaluation
As
we mentioned in Section 5.1.2, it is possible to construct a deterministic
evaluator from the inference rules. An experimental implementation
of Pebble, without a parser, was made in Prolog by Glen Stone at Manchester
University. A later one in ML, with a parser, was made at Edinburgh
by Hugh Stabler, implementing this paper except for inferred types
and extended types. Neither of these had pretensions to efficiency, but they
checked out the semantics and uncovered one or two bugs.
6. CONCLUSION
We have presented both an informal and a formal
treatment of the Pebble language, which adds to the type lambda
calculus a systematic treatment of sets of labelled values, and an
explicit form of polymorphism. Pebble can give a simple
account of many constructs for programming in
the large, and we have demonstrated this with a number of
examples. The language derives its power from its ability to
maniplate large, structured objects without delving into
their contents, and from the uniform use of A abstraction for all its entities.
A number
of areas
are open for further work:
-
Assignment, discussed briefly in Section 3.5.
-
Exception-handling, as an abbreviation for
returning a union result and testing for some of the cases,
-
Concurrency. We do not have any ideas about how
this is related to the rest of Pebble.
- A more mathematical
semantics for the
language (cf. Cardelli,
1986). Proof of the
soundness of the
type-checking, and an exploration of its limitations.
ACKNOWLEDGMENTS
We
thank a number of people for helpful discussions over an extended period,
particularly Luca
Cardelli, Joseph Goguen, David MacQueen, Gordon Plotkin, Ed Satterthwaite, and
Eric Schmidt.
Valuable feedback on the ideas and their presentation was obtained from members
of the IFIP Working
Group 2.3. We are grateful to the referees for corrections and suggestions. Much of our work was
supported by the Xerox Palo Alto Research Center. Rod Burstall also had support from
the Science and Engineering Research Council, and he was enabled to complete this work
by a British Petroleum Venture Research Fellowship and a SERC Senior
Fellowship. We thank Eleanor Kerse for kindly typing the manuscript in Scribe format through several revisions and Oliver Schoett for
Scribing the inference rules
RECEIVED October 16, 1985;
ACCENT!) October 27, 1988
REFERENCES
Minim, R., AND Lomc,o, G. (1986),
Type-free compiling of parametric types, in "IFIP
Conference on Formal Description
of Programming Languages, Ebberup, DK."
BAUER, F. L. et al. (1978), Towards a wide spectrum
language to support program
specification and program
development, SIGPLAN Notices 13, 15-24.
BuasrALL,
R. (1984), Programming with modules as typed functional programming, in "Proc.
·
International Conference on Fifth Generation Computing Systems, ICOT,
Tokyo."
BURSIALL, R., AND GOGUEN, J. (1977), Putting theories together to make
specifications,
in "5th
Joint International Conference on Artificial Intelligence, Combridge, MA,"
pp. 1045-1058.
CARow.1, L. (1984), A
semantics of multiple inheritance, "Lecture Notes in Computer Science Vol. 173," pp. 51-68, Springer•Verlag,
Berlin/New York.
CARDELLI, L. (1986), "A Polymorphic Lambda Calculus
with Type: Type," Report 10, Digital Equipment Corp. Systems Research Center, Palo Alto, CA.
DEMERS, A., AND
DONADUE, J. (1980),
Datatypes, parameters and type-checking, in "7th ACM Symposium on Principles of
Programming Languages, Las Vegas," pp. 12-23.
GIRARD,
J-Y. (1972), "Interpretation Fonctionelle et
Elimination des Coupures dans
l'Arithmetique
d'Ordre Superieur," These de Doctoral d'etat, University of Paris. GORDON, M., MILNI:R, R., AND Wnoswoarti, C. (1979), Edinburgh
LCF, "Lecture Notes in
Computer
Science Vol. 78," Springer-Verlag, Berlin/New York.
HARPER, R., MAcQuEEN, D., AND MILNER, R. L (1986), Standard ML, Computer Science Department, Edinburgh University,
Report ECS-LECS-86-2.
LArapsoN, li., AND Schram, E. (1983), Practical use of a polymorphic
applicative language, in "10th ACM Symposium on Principles of
Programming Languages, Austin."
LAMPSON. B. W. (1983), "A Description of the Cedar
Language," Report CSL-83-15, Xerox Palo Alto Research Center.
LANDIN, P. (1964), The next 700 programming languages, Comm. ACM 9, 157-166.
MAcOtirEN,
D., AND Stub, R. (1982), A higher order polymorphic type system
for applicative
languages, in "Symposium on Lisp and
Functional Programming, Pittsburgh, PA."
pp. 243-252.
MACQUITN,
D., PLOTKIN. G., AND SETIII, R. (1984), An ideal model for recursive polymorphic types, in "11th ACM Symposium on Principles of
Programming Languages, Salt Lake
City."
MACQUIEN, D. (1984), "Modules for Standard ML (Draft),"
Computer Science Department, Edinburgh University.
MARTIN-LOP, P. (1973), An intuitionistic theory
of types: Predicative part, in "Logic
Colloy. '73" (II.
E. Rose and J. C. Shepherdson, Eds.), pp. 73-118, North-I lolland, Amsterdam/New York.
MCCRACKEN, N. (1979), "An Investigation of a
Programming Language with a Polymorphic
Type Structure," Ph. D.
thesis, Computer and Information Science, Syracuse University. MILNER. R. (1978), A theory of type polymorphism in programming, J. Comput. System Sci.
17(3), 348-375.
Mimit:LL, J., MAYITURY, W., AND SWEET,
R. (1979), "Mesa
Language Manual," Report CSL-79-3, Xerox Palo Alto Research Center.
PEPPER, P. (1979), "A study on Transformational
Semantics," Dissertation, Fachbereich Mathematik, Technische Universitill Munchen.
PLOTKIN, G. (1981), "A Structural Approach to
Operational Semantics," Computer Science Department Report, Aarhus
University.
PLOTKIN. G., AND MITCHELL, J. (1985), Abstract
Types have Existential Type in "Twelfth
International
Conference on Principles of Programming Languages, New Orleans." RiANot.hs, J.
(1974), Towards a theory of type structure, "Lecture Notes in Computer
Science
Vol. 19," pp. 408-425,
Springer-Verlag, Berlin/New York.
REYNOLDS, J. (1983),
Types, abstraction and parametric polymorphism, in IttfOrm. Process., 83.
Schmiol, E. (1982),
"Controlling Large Software Development in a Distributed Environment," Report CSL-82-7, Xerox
Palo Alto Research Center.
